توليد النص - الذكاء الاصطناعي - ثالث ثانوي
الجزء الأول
1. أساسيات الذكاء الاصطناعي


2. خوارزميات الذكاء الاصطناعي
3. معالجة اللغات الطبيعية
الجزء الثاني
4. التعرف على الصور
5. خوارزميات التحسين واتخاذ القرار
الجزء الأول
1. أساسيات الذكاء الاصطناعي
2. خوارزميات الذكاء الاصطناعي
3. معالجة اللغات الطبيعية
الجزء الثاني
4. التعرف على الصور
5. خوارزميات التحسين واتخاذ القرار
 01:27
01:27



172 الدرس الثالث توليد النص رابط الدرس الرقمي www.ien.edu.sa توليد اللغات الطبيعية (Natural Language Generation ( NLG توليد اللغات الطبيعية (NLG) هو أحد فروع معالجة اللغات الطبيعية (NLP) التي تركّز على توليد النصوص البشرية باستخدام خوارزميات الحاسب . الهدف من توليد اللغات الطبيعية (NLG) هو توليد اللغات المكتوبة أو المنطوقة بصورة طبيعية ومفهومة للبشر دون الحاجة إلى تدخل بشري. توجد العديد من المنهجيات المختلفة لتوليد اللغات الطبيعية مثل: المنهجيات المستندة إلى القوالب والمستندة إلى القواعد، والمستندة إلى تعلُّم الآلة. علوم الحاسب معالجة اللغات الطبيعية : (Natural Language Processing-NLP) معالجة اللغات الطبيعية (NLP) هو أحد فروع الذكاء الاصطناعي الذي يمنح أجهزة الحاسب القدرة على محاكاة اللغات البشرية الطبيعية. معالجة اللغات الطبيعية علم اللغويات الذكاء توليد اللغات الطبيعية الاصطناعي *(Natural Language Generation-NLG) توليد اللغات الطبيعية (NLG) هي عملية توليد شكل 3.25 مُخطَّط فن (Venn) لمعالجة اللغات الطبيعية (NLP) النصوص البشرية باستخدام الذكاء الاصطناعي (AI). جدول :3.4 تأثير توليد اللغات الطبيعية CHID !? يُستخدم توليد اللغات الطبيعية (NLG لتوليد المقالات والتقارير الإخبارية، والمحتوى المكتوب آليًا مما يوفّر الوقت، ويساعد الأشخاص في التركيز على المهام الإبداعية أو المهام عالية المستوى. يمكن الاستفادة من ذلك في تحسين كفاءة وفعالية روبوت الدردشة لخدمة العملاء وتمكينه من تقديم ردود طبيعية ومفيدة لأسئلتهم واستفساراتهم. يمكن الاستفادة من توليد اللغات الطبيعية (NLG) في تحسين إمكانية الوصول لذوي الإعاقة أو لذوي الحواجز اللغوية، بتمكينهم من التواصل مع الآلات بطريقة طبيعية وبديهية تناسبهم. وزارة التعليم Ministry of Education 2024-1446

توليد اللغات الطبيعية

جدول 3.4: تأثير توليد اللغات الطبيعية
173 هناك أربع أنواع من توليد اللغات الطبيعية (NLG): توليد اللغات الطبيعية المبني على القوالب توليد اللغات الطبيعية المبني على الاختيار Template-Based NLG Selection-Based NLG يتضمن توليد اللغات الطبيعية المبني على القوالب استخدام يتضمن توليد اللغات الطبيعية المبني على الاختيار تحديد مجموعة قوالب محددة مسبقًا تحدد بنية ومحتوى النص المتولد. تُزَوِّد فرعية من الجمل أو الفقرات لإنشاء ملخص للنص الأصلي الأكبر هذه القوالب بمعلومات مُحدَّدة لتوليد النص النهائي. تُعدُّ هذه حجمًا. بالرغم من أن هذه المنهجية لا تُولّد نصوصًا جديدة، إلا المنهجية بسيطة نسبيًا وتحقق فعالية في توليد النصوص للمهام أنها مُطبقة عمليًا على نطاق واسع؛ وذلك لأنّها تأخذ العينات من المحدَّدة والمعرَّفة جيدًا. من ناحية أخرى ، قد تواجه صعوبة مع مجموعة من الجمل المكتوبة بواسطة البشر، يمكن الحد من المهام المفتوحة أو المهام التي تتطلب درجة عالية من التباين في مخاطرة توليد النصوص غير المتنبئ بها أو ضعيفة البنية. على النص المُوَلَّد . على سبيل المثال، قالب تقرير حالة الطقس ربما سبيل المثال، مُولّد تقرير الطقس المبني على الاختيار قد يضم يبدو كما يلي: Today in [city]، it is [temperature degrees قاعدة بيانات من العبارات مثل It is not outside (الطقس .[with [weather condition اليوم في المدينة، درجة حار بالخارج ، و The temperature is rising (درجة الحرارة و الحرارة هي [درجة الحرارة مئوية وحالة الطقس].). ترتفع ، و Expect sunny skies تنبؤات بطقس مشمس . توليد اللغات الطبيعية المبني على القواعد توليد اللغات الطبيعية المبني على تعلم الآلة Rule-Based NLG Machine Learning-Based NLG يستخدم توليد اللغات الطبيعية المبني على القواعد مجموعة يتضمن توليد اللغات الطبيعية المبني على تعلُّم الآلة تدريب نموذج من القواعد المحدَّدة مُسبقًا لتوليد النص. قد تحدّد هذه تعلُّم الآلة على مجموعة كبيرة من بيانات النصوص البشرية. القواعد طريقة تجميع الكلمات والعبارات لتشكيل الجمل، أو يتعلّم النموذج أنماط النص وبنيته ، ومن ثَمّ يمكنه توليد النص كيفية اختيار الكلمات وفقًا للسياق المستخدمة فيه. عادةً الجديد الذي يشبه النص البشري في الأسلوب والمحتوى. قد تكون تُستخدم هذه القواعد لتصميم روبوت الدردشة لخدمة المنهجية أكثر فعالية في المهام التي تتطلب درجة عالية من التباين العملاء. قد يكون من السهل تطبيق الأنظمة المبنية على في النص المولّد . وقد تتطلب المنهجية مجموعات أكبر من بيانات القواعد . وفي بعض الأحيان قد تتسم بالجمود ولا تُولّد مُخرجات التدريب والموارد الحسابية. تبدو طبيعية. ول استخدام توليد اللغات الطبيعية المبني على القوالب Using Template-Based NL توليد اللغات الطبيعية المبني على القوالب بسيط نسبيًا وقد يكون فعالاً في توليد النصوص للمهام المحدَّدة والمعرفة مثل إنشاء التقارير أو توصيف البيانات إحدى مميزات توليد اللغات الطبيعية المبني على القوالب هو سهولة التطبيق والصيانة. يُصمِّم الأشخاص القوالب دون الحاجة إلى خوارزميات تعلم الآلة المعقدة أو مجموعات كبيرة من بيانات التدريب. وهذا يجعل توليد اللغات الطبيعية المبني على القوالب هو الخيار المناسب للمهام التي تكون ذات بنية ومحتوى نص محدّدين، دون الحاجة إلى إجراء تغييرات كبيرة. تَستند قوالب توليد اللغات الطبيعية (NLG) إلى أي بنية لغوية مُحدَّدة مُسبقًا. إحدى الممارسات الشائعة هي إنشاء القوالب التي تتطلب كلمات بوسوم محددة كجزء من الكلام لإدراجها في الفراغات المحددة ضمن الجملة. وسوم POS و PRON VERB DET ADJ NOUN وسوم أقسام الكلام Part of Speech (POS) Tags وسوم أقسام الكلام Part of Speech ، التي تُعرَّف كذلك باسم هي قيم تُخصَّص للكلمات في النص للإشارة إلى البناء النحوي للكلمات، أو جزء الكلام في الجملة على سبيل المثال، قد تكون upgrade الكلمة اسمًا أو فعلًا أو صفةً أو ظرفًا ، إلخ ، وتُستخدم وسوم أقسام الكلام شكل 3.26 مثال على عملية وسم أقسام الكلام في معالجة اللغات الطبيعية (NLP) لتحليل بنية النص وفهم معناه. early an want وزارة التعليم Ministry of Education 2024-1446

توليد اللغات الطبيعية المبني على القوالب
توليد اللغات الطبيعية المبني على الاختيار
توليد اللغات الطبيعية المبني على القواعد
توليد اللغات الطبيعية المبني على تعلم الآلة
استخدام توليد اللغات الطبيعية المبني على القوالب
وسوم أقسام الكلام
تحليل بناء الجمل Syntax Analysis يُستخدم تحليل بناء الجمل عادةً إلى جانب وسوم أقسام الكلام (POS) في توليد اللغات الطبيعية المبني على القوالب لضمان قدرة القوالب على توليد النصوص الواقعية. يتضمن تحليل بناء الجمل التعرّف على أجزاء الكلام في الجمل، والعلاقات بينها لتحديد البناء النحوي للجُملة تتضمن الجُملة أنواعًا مختلفة من عناصر بناء الجملة، مثل: الفعل ( Predicate) هو قسم الجُملة الذي يحتوي على الفعل. وهو عادةً يعبر عمّا عما يقوم به الفاعل أو عما يحدث. • الفاعل (Subject) هو قسم الجملة الذي يُنفّذ الفعل. • المفعول به ( Direct Object) هو اسم أو ضمير يشير إلى الشخص أو الشيء الذي يتأثر مباشرةً بالفعل. يستخدم المقطع البرمجي التالي مكتبة ووندر ووردز (Wonderwords) التي تتبع منهجية بناء الجمل لعرض بعض الأمثلة على توليد اللغات الطبيعية المبني على القوالب وزارة التعليم Ministry of Education 2024-1446 %%capture !pip install wonderwords # used to generate template-based randomized sentences from wonderwords.random_sentence import RandomSentence # make a new generator with specific words generator RandomSentence ( # specify some nouns nouns=["lion", "rabbit", "horse", "table"], verbs=["eat","run", "laugh"], # specify some verbs. adjectives=['angry','small']) # specify some adjectives. # generates a sentence with the following template: [subject (noun)] [predicate (verb)] generator.bare_bone_sentence() 'The table runs.' # generates a sentence with the following template: # the [(adjective)] [subject (noun)] [predicate (verb)] [direct object (noun)] generator.sentence( ) 'The small lion runs rabbit.' توضح الأمثلة بالأعلى أنه، بينما يُستخدَم توليد اللغات الطبيعية المبني على القوالب لتوليد الجمل وفق بنية مُحدَّدة ومُعتمدة مُسبقًا، إلا أنّ هذه الجُمل قد لا تكون ذات مغزى عملي. وعلى الرغم من إمكانية تحسين دقة النتائج إلى حدٍ كبير بتحديد قوالب متطورة ووضع المزيد من القيود على استخدام المفردات، إلا أن هذه المنهجية غير عملية لتوليد النصوص الواقعية على نطاق واسع. فبدلا من إنشاء القوالب المحدَّدة مُسبقًا، تُستخدم المنهجية الأخرى لتوليد اللغات الطبيعية القائمة على القوالب البنية والمفردات نفسها المكوِّنة لأي جملة حقيقية كقالب ديناميكي متغير. تتبنى دالة ( )paraphrase هذه المنهجية. 174

تحليل بناء الجمل
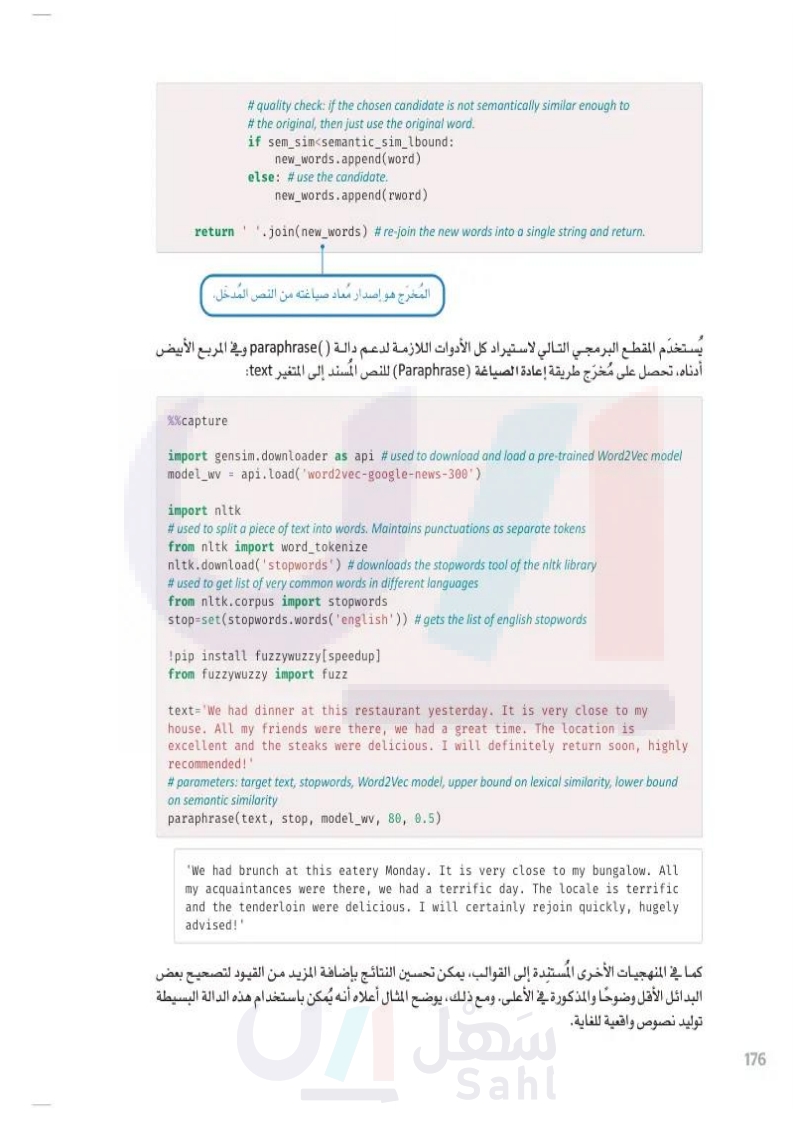
175 وزارة التعليم Ministry of Education 2024-1446 دالة (Paraphrase تُقسم الدالة في البداية النص المكوَّن من فقرة إلى مجموعة من الجمل. ثم تحاول استبدال كل كلمة في الجملة بكلمة أخرى متشابهة دلاليًا. يُقيَّم التشابه الدلالي بواسطة نموذج الكلمة إلى المتَّجه (Word Vec) الذي درسته في الدرس السابق. قد يوصي نموذج الكلمة إلى المتَّجه (Word2Vec باستبدال الكلمة في الجملة بكلمة أخرى مشابهة لها، مثل: استبدال apple ( تفاحة بـ apples تفاح ، ولتجنب مثل هذه الحالات تُستخدم دالة مكتبة fuzzyWuzzy الشهيرة لتقييم تشابه المفردات بين الكلمة الأصلية والكلمة البديلة. الدالة نفسها موضحة بالأسفل: def paraphrase(text:str, #text to be paraphrased stop:set, # set of stopwords model_wv, # Word2Vec Model lexical_sim_ubound:float, # upper bound on lexical similarity semantic_sim_lbound:float # lower bound on semantic similarity ): words=word_tokenize(text #tokenizes the text to words new_words=[] # new words that will replace the old ones. for word in words: # for every word in the text topn=10) word_l=word.lower() #lower-case the word. # if the word is a stopword or is not included in the Word2Vec model, do not try to replace it. if word_l in stop or word_l not in model_wv: new_words.append(word) # append the original word else: # otherwise # get the 10 most similar words, as per the Word2Vec model. # returned words are sorted from most to least similar to the original. # semantic similarity is always between O and 1. replacement_words=model_wv.most_similar(positive=[word_l], # for each candidate replacement word for rword, sem_sim in replacement_words: # get the lexical similarity between the candidate and the original word. # the partial_ratio function returns values between 0 and 100. # it compares the shorter of the two words with all equal-sized substrings # of the original word. lex_sim=fuzz.partial_ratio(word_l,rword) # if the lexical sim is less than the bound, stop and use this candidate. if lex_sim<lexical_sim_ubound: break fuzz تشير إلى مكتبة fuzzyWuzzy

دالة Paraphrase()
وزارة التعليم Ministry of Education 2024-1446 return #quality check: if the chosen candidate is not semantically similar enough to # the original, then just use the original word. if sem_sim<semantic_sim_lbound: new_words.append(word) else: # use the candidate. new_words.append(rword) .join(new_words) # re-join the new words into a single string and return. المخرج هو إصدار مُعاد صياغته من النص المدخل. يُستخدم المقطع البرمجي التالي لاستيراد كل الأدوات اللازمة لدعم دالة )) paraphrase وفي المربع الأبيض أدناه، تحصل على مخرج طريقة إعادة الصياغة (Paraphrase) للنص المسند إلى المتغير text: %%capture import gensim.downloader as api #used to download and load a pre-trained Word2Vec model model_wv = api.load('word2vec-google-news-300') import nltk # used to split a piece of text into words. Maintains punctuations as separate tokens from nltk import word_tokenize nltk.download('stopwords') # downloads the stopwords tool of the nltk library # used to get list of very common words in different languages from nltk.corpus import stopwords stop-set(stopwords.words('english')) # gets the list of english stopwords !pip install fuzzywuzzy [speedup] from fuzzywuzzy import fuzz text='We had dinner at this restaurant yesterday. It is very close to my house. All my friends were there, we had a great time. The location is excellent and the steaks were delicious. I will definitely return soon, highly recommended!' # parameters: target text, stopwords, Word2Vec model, upper bound on lexical similarity, lower bound on semantic similarity paraphrase(text, stop, model_wv, 80, 0.5) 'We had brunch at this eatery Monday. It is very close to my bungalow. All my acquaintances were there, we had a terrific day. The locale is terrific and the tenderloin were delicious. I will certainly rejoin quickly, hugely advised!' كما في المنهجيات الأخرى المستندة إلى القوالب يمكن تحسين النتائج بإضافة المزيد من القيود لتصحيح بعض البدائل الأقل وضوحًا والمذكورة في الأعلى. ومع ذلك، يوضّح المثال أعلاه أنه يُمكن باستخدام هذه الدالة البسيطة توليد نصوص واقعية. 176

دالة مكتبة fuzzywuzzy الشهيرة لتقييم تشابه بين الكلمات الأصلية والكلمة البديلة
استخدام توليد اللغات الطبيعية المبني على الاختيار Using Selection-Based NLG في هذا القسم، ستستعرض منهجية عملية لاختيار نموذج من الجمل الفرعية من وثيقة مُحدَّدة. هذه المنهجية تُجسد استخدام ومزايا توليد اللغات الطبيعية المبنيّ على الاختيار يستند إلى لبنتين رئيستين: • نموذج الكلمة إلى المتَّجه (Word2Vec) المستخدم لتحديد أزواج الكلمات المتشابهة دلاليا. • مكتبة Networkx الشهيرة ضمن لغة البايثون المستخدمة لإنشاء ومعالجة أنواع مختلفة من بيانات الشبكة. النَّص المدخل الذي سيُستخدم في هذا الفصل هو مقالة إخبارية نُشرت بعد المباراة النهائية لكأس العالم 2022. # reads the input document that we want to summarize with open('article.txt',encoding='utf8',errors='ignore') as f: text=f.read() text[:100] # shows the first 100 characters of the article 'It was a consecration, the spiritual overtones entirely appropriate. Lionel Messi not only emulated و في البداية، يُرمز النص باستخدام مكتبة re والتعبير النمطي نفسه المستخدم في الوحدات السابقة: import re # used for regular expressions # tokenize the document, ignore stopwords, focus only on words included in the Word2Vec model. tokenized_doc=[word for word in re.findall(r'\b\w\w+\b',text.lower()) if word not in stop and word in model_wv] # get the vocabulary (set of unique words). vocab=set(tokenized_doc) مكتبة Networkx لک و يمكن الآن نمذجة مفردات المستند في مُخطَّط موزون (Weighted Graph). توفر مكتبة Networkx في لغة البايثون مجموعة واسعة من الأدوات لإنشاء وتحليل المخطّطات. في توليد اللغات الطبيعية المبني على الاختيار، يُساعد تمثيل مفردات الوثيقة في مخطط موزون في تحديد العلاقات بين الكلمات وتسهيل اختيار العبارات والجمل ذات الصلة. في المُخطَّط الموزون، تُمثل كل عُقدة كلمةً أو مفهومًا ، وتُمثل الحواف بين العُقد العلاقات بين هذه المفاهيم. تُعبر الأوزان على الحواف عن قوة هذه العلاقات، مما يسمح لنظام توليد اللغات الطبيعية بتحديد المفاهيم الأقوى ارتباطًا. عند توليد النصوص يُستخدم المخطّط الموزون للبحث عن العبارات والجمل استنادًا إلى العلاقات بين الكلمات. على سبيل المثال، قد يستخدم النظام المخطط للبحث عن الكلمات والعبارات الأكثر ارتباطًا لوصف كيان مُحدَّد ثم استخدام هذه الكلمات لتحديد الجملة الأكثر ملاءمةً من قاعدة بيانات النظام. و لک و منزل 2 الموقع 2 1 مطعم 3 عشاء 2 2 1 موصي به 3 لذيذ شكل :3.27 مثال على مُخطّط موزون لـ Networkx 177 وزارة التعليم Ministry of Education 2024-1446

مكتبة Networkx
استخدام توليد اللغات الطبيعية المبني على الاختيار
fi دالة ()Build_graph تُستخدم دالة ( )Build_graph مكتبة Networkx لإنشاء مُخطّط عُقدة واحدة لكل كلمة ضمن مفردات محددة. يتضمن: • حافة بين كل كلمتين. الوزن على الحافة يساوي التشابه الدلالي بين الكلمات، المحسوب بواسطة أداة Doc2Vec وهي أداة معالجة اللغات الطبيعية المخصصة لتمثيل النص كمثَّجَه وهي تعميم لمنهجية نموذج الكلمة إلى المتَّجه .(Word2Vec) الدالة مخطّطًا ذا عُقدة واحدة لكل كلمة في المفردات المحدَّدة. توجد كذلك حافة بين عقدتين إذا كان تشابه نموذج الكلمة إلى المتَّجه (Word2Vec) أكبر من الحد المعطى. ترسم # tool used to create combinations (e.g. pairs, triplets) of the elements in a list from itertools import combinations import networkx as nx #python library for processing graphs def build_graph(vocab:set, # set of unique words model_wv # Word2Vec model ): # gets all possible pairs of words in the doc pairs combinations (vocab,2) G=nx.Graph() # makes a new graph for w1, w2 in pairs: # for every pair of words w1, w2 sim-model_wv.similarity(w1, w2) # gets the similarity between the two words G.add_edge(w1, w2, weight=sim) return G # creates a graph for the vocabulary of the World Cup document G=build_graph(vocab, model_wv) # prints the weight of the edge (semantic similarity) between the two words G['referee']['goalkeeper'] {'weight': 0.40646762} وبالنظر إلى ذلك المُخطَّط المبني على الكلمة، يمكن تمثيل مجموعة من الكلمات المتشابهة دلاليا في صورة عناقيد من العُقد المتصلة معًا بواسطة حواف عالية و الوزن. يُطلق على عناقيد العقد كذلك المجتمعات ( Communities) مخرج المخطّط هو مجموعة بسيطة من الرؤوس والحواف الموزونة. لم تُجرى عملية التجميع حتى الآن لإنشاء المجتمعات. في الشكل 3.28 تُستخدم ألوان مختلفة لتمييز المجتمعات في المُخطَّط المذكور بالمثال السابق. شكل 3.28: المجتمعات في المخطّط وزارة التعليم Ministry of Education 2024-1446 178

دالة Build_graph()
179 وزارة التعليم Ministry of Education 2024-1446 خوارزمية لوفان Louvain Algorithm تتضمن مكتبة Networkx العديد من الخوارزميات لتحليل المُخطَّط والبحث عن المجتمعات. واحدة من الخيارات الأكثر فعالية هي خوارزمية لوفان التي تعمل عبر تحريك العقد بين المجتمعات حتى تجد بنية المجتمع التي تمثل الربط الأفضل في الشبكة الضمنية. دالة ( )Get_communities تستخدم الدالة الآتية خوارزمية لوفان للبحث عن المجتمعات في المخطَّط المبني على الكلمات. تحسب الدالة كذلك ثم تكون المخرجات في صورة قاموسين: مؤشر الأهمية لكل مجتمع على حده word_to_community الذي يربط الكلمة بالمجتمع. community_scores الذي يربط المجتمع بدرجة الأهمية. الدرجة تساوي مجموع تكرار الكلمات في المجتمع. على سبيل المثال، إذا كان المجتمع يتضمن ثلاثة كلمات تظهر 5 و8 و6 مرات في النص، فإن مؤشّر المجتمع حينئذ يساوي 19 ومن ناحية المفهوم، يمثل المؤشر جزءا من النص الذي يضُمُّه المجتمع. from networkx. algorithms.community import louvain_communities from collections import Counter # used to count the frequency of elements in a list def get_communities( G, # the input graph tokenized_doc:list): #the list of words in a tokenized document # gets the communities in the graph communities=louvain_communities(G, Weight='weight') word_cnt=Counter(tokenized_doc )# counts the frequency of each word in the doc word_to_community={}# maps each word to its community community_scores={}# maps each community to a frequency score for comm in communities: # for each community # convert it from a set to a tuple so that it can be used as a dictionary key. comm=tuple(comm) score=0 #initialize the community score to 0. for word in comm: # for each word in the community word_to_community[word]=comm #map the word to the community score+=word_cnt[word] # add the frequency of the word to the community's score. community_scores[comm]=score #map the community to the score. return word_to_community, community_scores

خوارزمية لوفان
دالة Get_communities ()
وزارة التعليم Ministry of Education 2024-1446 word_to_community, community_scores = get_communities(G,tokenized_doc) word_to_community['player'][:10] #prints 10 words from the community of the word 'team' ('champion', 'stretch' 'finished', 'fifth', 'playing', 'scoring', 'scorer', 'opening', 'team', 'win' و لل الآن بعد ربط كل الكلمات بالمجتمع، وربط المجتمع بمؤشر الأهمية، ستكون الخطوة التالية هي استخدام هذه المعلومات لتقييم أهمية كل جملة في المستند الأصلي. دالة ( )evaluate_sentences مصممة لهذا الغرض. دالة ( )Evaluate_sentences المستند إلى جُمل، ثم حساب مؤشر الأهمية لكل جُملة، استنادًا إلى الكلمات التي تتضمنها. بتقسيم تبدأ الدالة تكتسب كل كلمة مؤشر الأهمية من المجتمع الذي تنتمي إليه. على سبيل المثال، لديك جملة مكونة من خمسة كلمات 5 ،4 ،3 ،2 ،w1 . الكلمتان W1 و w2 تنتميان إلى مجتمع بمؤشر قيمته 25 ، والكلمتان w3 و W4 تنتميان إلى مجتمع بمؤشر قيمته 30 ، والكلمة W5 تنتمي إلى مجتمع بمؤشر قيمته 15 مجموع مؤشرات الجمل هو 25+25+30+30+15=125. تَستخدم الدالة بعد ذلك هذه المؤشرات لتصنيف الجمل في ترتيب تنازلي من الأكثر إلى الأقل أهمية. from nltk import sent_tokenize # used to split a document into sentences def evaluate_sentences(doc:str, #original document word_to_community: dict,# maps each word to its community community_scores:dict, # maps each community to a score model_wv): # Word2Vec model #splits the text into sentences sentences=sent_tokenize(doc) scored_sentences=[]# stores (sentence, score) tuples for raw_sent in sentences: # for each sentence #get all the words in the sentence, ignore stopwords and focus only on words that are in the Word2Vec model. sentence_words=[word for word in re.findall(r'\b\w\w+\b',raw_sent.lower()) #tokenizes if word not in stop and # ignores stopwords 180

خوارزمية لوفان للبحث في المجتمعات في المخطط المبني على الكلمات
دالة Evauate_sentences()
181 وزارة التعليم Ministry of Education 2024-1446 word in model_wv] # ignores words that are not in the Word2Vec model sentence_score=0 # the score of the sentence for word in sentence_words: # for each word in the sentence word_comm=word_to_community [word] # get the community of this word sentence score += community_scores [word_comm] # add the score of this community to the sentence score. scored sentences.append((sentence_score, raw_sent)) # stores this sentence and its total score # scores the sentences by their score, in descending order scored sentences-sorted (scored_sentences, key-lambda x:x[0], reverse=True) return scored_sentences scored sentences-evaluate_sentences (text, word_to_community, community_ scores, model_wv) len(scored_sentences) 61 Я المستنَد الأصلي إجمالي 61 جُملة، ويُستخدم المقطع البرمجي التالي للعثور على الجمل الثلاثة الأكثر يتضمن أهمية من بين هذه الجمل for i in range(3): print(scored_sentences[i],'\n') (3368, 'Lionel Messi not only emulated the deity of Argentinian football, Diego Maradona, by leading the nation to World Cup glory; he finally plugged the burning gap on his CV, winning the one title that has eluded him at the fifth time of asking, surely the last time.') - (2880, 'He scored twice in 97 seconds to force extra-time; the first a penalty, the second a sublime side-on volley and there was a point towards the end of regulation time when he appeared hell-bent on making sure that the additional period would not be needed.') (2528, 'It will go down as surely the finest World Cup final of all time, the most pulsating, one of the greatest games in history because of how Kylian Mbappé hauled France up off the canvas towards the end of normal time.')

تستخدم الدالة هذه المؤشرات لتصنيف الجمل في ترتيب تنازلي من الأكثر الى الأقل أهمية 1
وزارة التعليم Ministry of Education 2024-1446 print(scored_sentences [-1]) # prints the last sentence with the lowest score print() print(scored_sentences[30]) # prints a sentence at the middle of the scoring scale (0, 'By then it was 2-0.') (882, 'Di Maria won the opening penalty, exploding away from Ousmane Dembélé before being caught and Messi did the rest.') النتائج تؤكد أن هذه المنهجية تُحدِّد بنجاح الجمل الأساسية التي تستنبط النقاط الرئيسة في المستند الأصلي، مع تعيين مؤشرات أقل للجُمل الأقل دلالةً تُطبَّق المنهجية نفسها كما هي لتوليد ملخص لأي وثيقة مُحدَّدة. استخدام توليد اللغات الطبيعية المبني على القواعد لإنشاء روبوت الدردشة Using Rule-Based NLG to Create a Chatbot في هذا القسم، ستُصمِّم روبوت دردشة Chatbot) وفق المسار المحدَّد الموصي به بالجمع بين قواعد المعرفة الرئيسة للأسئلة والأجوبة والنموذج العصبي تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات SBERT) ، ويشير هذا إلى أن نقل التعلم المستخدم في تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) له البنية نفسها كما في تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (all-MiniLM-L6-v2 (SBERT وسوف يهيَّأ بشكل دقيق مُهمَّة أخرى غير تحليل المشاعر، وهي: توليد اللغات الطبيعية. و 1. تحميل نموذج تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات المدرب مُسبقًا Load the Pre-Trained SBERT Model الخطوة الأولى هي تحميل نموذج تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) المُدرَّب مُسبقًا: %%capture from sentence_transformers import Sentence Transformer, util model_sbert = SentenceTransformer('all-MiniLM-L6-v2') 2. إنشاء قاعدة معرفة بسيطة Create a Simple Knowledge Base الخطوة الثانية هي إنشاء قاعدة معرفة بسيطة لتحديد النص البرمجي المكون من الأسئلة والأجوبة التي يستخدمها روبوت الدردشة. يتضمن النص البرمجي 4 أسئلة ( السؤال 1 إلى (4) والأجوبة على كل سؤال ( الإجابة 1 إلى 4) . كل إجابة مكونة من مجموعة من الخيارات كل خيار يتكون من قيمتين فقط، تُمثَّل القيمة الثانية السؤال التالي الذي يستخدمه روبوت الدردشة. إذا كان هذا هو السؤال الأخير ، ستكون القيمة الثانية خالية. هذه الخيارات تمثل الإجابات الصحيحة المحتملة على الأسئلة المعنية بها. على سبيل المثال، الإجابة على السؤال الثاني لها خياران محتملان Java"، None] and [Python" ، None"] (["جافا " ، لا يوجد] و ["البايثون" ، لا يوجد ] ) . كل خيار مكون من قيمتين: • النص الحقيقي للإجابة المقبولة مثل : Java ) جافا ) أو Courses on Marketing ) دورات تدريبية في التسويق). مُعرِّف يشير إلى السؤال التالي الذي سيطرحه روبوت الدردشة عند تحديد هذا الخيار. على سبيل المثال، إذا حدد المستخدم خيار "3" ، " Courses on Engineering"] (["دورات تدريبية في الهندسة"، "3"]) كإجابة على السؤال الأول، يكون السؤال التالي الذي سيطرحه روبوت الدردشة هو السؤال الثالث. 182

يستخدم المقطع البرمجي التالي للعثور على الجمل الثلاثة الأكثر أهمية من بين هذه الجمل 1
استخدام توليد اللغات الطبيعية المبني على القواعد لإنشاء روبوت الدردشة
تحميل نموذج تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات المدرب مسبقا
إنشاء قاعدة معرفة بسيطة
183 وزارة التعليم Ministry of Education 2024-1446 يمكن توسيع قاعدة المعرفة البسيطة لتشمل مستويات أكثر من الأسئلة والأجوبة، وتجعل روبوت الدردشة أكثر ذكاءً. QA = { "Q1":"What type of courses are you interested in?", "A1":[["Courses in Computer Programming","2"], ["Courses in Engineering","3"], ["Courses in Marketing","4"]], "Q2":"What type of Programming Languages are you interested in?", "A2":[["Java",None],["Python",None]], "Q3":"What type of Engineering are you interested in?", "A3":[["Mechanical Engineering", None], ["Electrical Engineering", None]], "Q4": "What type of Marketing are you interested in?", "A4":[["Social Media Marketing",None],["Search Engine Optimization", None]] } دالة ()Chat في النهاية، تُستخدم دالة ( ) Chat لمعالجة قاعدة المعرفة وتنفيذ روبوت الدردشة. بعد طرح السؤال، يقرأ روبوت الدردشة رد المستخدم. إن كان الرد مشابهًا دلاليًا لأحد خيارات الإجابات المقبولة لهذا السؤال، يُحدد ذلك الخيار وينتقل روبوت الدردشة إلى السؤال التالي. إن لم يتشابه الرد مع أي من الخيارات، يُطلب من المستخدم إعادة صياغة الرد. تُستخدم دالة تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) لتقييم مؤشر التشابه الدلالي بين الرد وكل الخيارات المُرشَّحة. يُعدُّ الخيار متشابها إذا كان المؤشر أعلى من متغير الحد الأدنى sim_lbound. import numpy as np # used for processing numeric data def chat(QA:dict, #the Question-Answer script of the chatbot model_sbert, #a pre-trained SBERT model sim_lbound:float): #lower bound on the similarity between the user's response and the closest candidate answer qa_id='1' # the OA id while True: # an infinite loop, will break in specific conditions print('>>',QA['Q'+qa_id]) #prints the question for this qa_id candidates=QA["A"+qa_id] # gets the candidate answers for this qa_id print(flush=True) # used only for formatting purposes response=input( ) #reads the user's response # embed the response response_embeddings = model_sbert.encode( [response], convert_to_ tensor=True) # embed each candidate answer. x is the text, y is the qa_id. Only embed x.

يمكن توضيح قاعدة المعرفة البسيطة لتشمل مستويات أكثر من الأسئلة والأجوبة وتجعل روبوت الدردشة الأكثر ذكاء
دالة Chat()
وزارة التعليم Ministry of Education 2024-1446 candidate_embeddings convert_to_tensor=True) = model_sbert.encode((x for x,y in candidates], # gets the similarity score for each candidate similarity_scores = util.cos_sim (response_embeddings, candidate_ embeddings) # finds the index of the closest answer. #np.argmax(L) finds the index of the highest number in a list L winner_index=np.argmax(similarity_scores[0]) # if the score of the winner is less than the bound, ask again. if similarity_scores [0] [winner_index] <sim_lbound: print('>> Apologies, I could not understand you. Please rephrase your response.') continue #gets the winner (best candidate answer) winner candidates [winner_index] # prints the winner's text print('\n>> You have selected: ', winner[0]) print() qa_id=winner[1] # gets the qa_id for this winner if qa_id==None: # no more questions to ask, exit the loop print('>> Thank you, I just emailed you a list of courses.') break أنظر إلى التفاعلين التاليين بين روبوت الدردشة والمستخدم: التفاعل الأول chat(QA, model_sbert, 0.5) >> What type of courses are you interested in? marketing courses >> You have selected: Courses on Marketing >> What type of Marketing are you interested in? seo >> You have selected: Search Engine Optimization >> Thank you, I just emailed you a list of courses. في التفاعل الأول، يفهم روبوت الدردشة أن المستخدم يبحث عن دورات تدريبية في التسويق. وكذلك ، روبوت الدردشة ذكي بالقدر الكافي ليفهم أن المصطلح SEO يشبه دلاليا مصطلح Search Engine Optimization (تحسين محركات البحث مما يؤدي إلى إنهاء المناقشة بنجاح. 184

دالة Chat() 1
التفاعل الأول
185 chat (QA, model_sbert, 0.5) التفاعل الثاني >> What type of courses are you interested in? cooking classes >> Apologies, I could not understand you. Please rephrase your response. >> what type of courses are you interested in? software courses >> You have selected: Courses on Computer Programming >> What type of Programming Languages are you interested in? C++ >> You have selected: Java >> Thank you, I just emailed you a list of courses. و في التفاعل الثاني، يفهم روبوت الدردشة أن Cooking Classes ( دروس الطهي لا تشبه دلاليا الخيارات الموجودة في قاعدة المعرفة. وهو ذكي بالقدر الكافي ليفهم أن Software courses ) الدورات التدريبية في البرمجة) يجب أن ترتبط بخيار Courses on Computer Programming (الدورات التدريبية في برمجة الحاسب . الجزء الأخير من التفاعل يسلط الضوء على نقاط الضعف يربط روبوت الدردشة بين رد المستخدم ++C و Java. على الرغم من أن لغتي البرمجة مرتبطتان بالفعل ويمكن القول بأنهما أكثر ارتباطًا من لغتي البايثون و ++C ، إلا أن الرد المناسب يجب أن يُوضّح أن روبوت الدردشة لا يتمتع بالدراية الكافية للتوصية بالدورات التدريبية في لغة ++C . إحدى الطرائق لمعالجة هذا القصور هي استخدام التشابه بين المفردات بدلًا من التشابه الدلالي للمقارنة بين الردود والخيارات ذات الصلة ببعض الأسئلة. استخدام تعلم الآلة لتوليد نص واقعي Using Machine Learning to Generate Realistic Text الطرائق الموضحة في الأقسام السابقة تستخدم القوالب ، والقواعد ، أو تقنيات التحديد لتوليد النصوص للتطبيقات المختلفة. في هذا القسم، ستتعرف على أحدث تقنيات تعلُّم الآلة المستخدمة في توليد اللغات الطبيعية (NLG). 2 جدول 3.5 تقنيات تعلم الآلة المتقدمة المستخدمة في توليد اللغات الطبيعية التقنية الوصف شبكة الذاكرة المطولة قصيرة تتكون شبكة الذاكرة المطولة قصيرة المدى (LSTM) من خلايا ذاكرة (Memory Cells) المدى Long Short-Term مرتبطة ببعض . عند إدخال سلسلة من البيانات إلى الشبكة، تتولى معالجة كل عنصر في السلسلة واحدًا تلو الآخر، وتُحدِّث الشبكة خلايا الذاكرة لتوليد مخرج لكل عنصر على حده. شبكات الذاكرة المطولة قصيرة المدى (LSTM) تناسب مهام توليد اللغات الطبيعية (NLG) لقدرتها على الاحتفاظ بالمعلومات من سلاسل البيانات ( مثل التعرّف Memory - LSTM) على الكلام أو الكتابة اليدوية) ومعالجة تعقيد اللغات الطبيعية. النماذج المبنية على المحولات النماذج المبنية على المحولات هي تلك التي تفهم اللغات البشرية وتولّدها، وتستند هذه النماذج في عملها إلى تقنية الانتباه الذاتي (Self-Attention) التي تمكّنها من فهم (Transformer-Based Models) العلاقات بين الكلمات المختلفة في الجمل. وزارة التعليم Ministry of Education 2024-1446

التفاعل الثاني
استخدام تعلم الآلة لتوليد نص واقعي
جدول 3.5: تقنيات تعلم الآلة المتقدمة المستخدمة في توليد اللغات الطبيعية
مُفكِّك الترميز (DECODERS) المخرج أنا طالب المرمز OUTPUT N OUTPUT 2 OUTPUT 1 (ENCODERS) LSTM LSTM LSTM المدخل INPUT N INPUT 2 INPUT 1 I am a student "today" "am" "[" شكل 3.30: المحول شكل 3.29 الذاكرة المطولة قصيرة المدى المحولات Transformers المحولات مناسبة لمهام توليد اللغات الطبيعية لقدرتها على معالجة البيانات المدخلة المتسلسلة بكفاءة. في نموذج المحولات، تُمرَّر البيانات المدخلة عبر المرمز الذي يُحوّل المدخلات إلى تمثيل مستمر، ثم يُمرَّر التمثيل عبر. مُفكِّك الترميز الذي يُولّد التسلسل المخرج إحدى الخصائص الرئيسة لهذه النماذج هي استخدام آليات الانتباه التي تسمح للنموذج بالتركيز على الأجزاء المُهمَّة من التسلسل في حين تتجاهل الأجزاء الأقل دلالةً. أظهرت نماذج المحوّلات كفاءة في توليد النص عالي الدقة للعديد من مهام توليد اللغات الطبيعية بما في ذلك ترجمة الآلة، والتلخيص، والإجابة على الأسئلة. نموذج الإصدار الثاني من المحول التوليدي مُسبَق التدريب GPT-2 Model في هذا القسم، ستستخدم الإصدار الثاني من المحوِّل التوليدي مُسبق التدريب (2-GPT ) وهو نموذج لغوي قوي طورته شركة أوبن أي آي (OpenAl) لتوليد النصوص المستندة إلى النص التلقيني المدخل بواسطة المستخدم. الإصدار الثاني من المحوِّل التوليدي مُسبق التدريب 2 - 2 Generative Pre-training Transformer ) مُدرَّب على مجموعة بيانات تضم أكثر من ثمان ملايين صفحة ويب ويتميز بالقدرة على إنشاء النصوص البشرية بعدة لغات وأساليب بنية الإصدار الثاني من المحوِّل التوليدي مُسبق التدريب (2-GPT) المبنية على المحول تسمح بتحديد التبعيات (Dependencies) بعيدة المدى وتوليد النصوص المتسقة ، وهو مُدرَّب للتنبؤ بالكلمة التالية وفقًا لكل الكلمات السابقة ضمن النص، وبالتالي يمكن استخدام النموذج لتوليد نصوص طويلة جدًا عبر التنبؤ المستمر وإضافة المزيد من الكلمات. وس و وزارة التعليم Ministry of Education 2024-1446 %%capture !pip install transformers !pip install torch import torch # an open-source machine learning library for neural networks, required for GPT2. from transformers import GPT2LMHeadModel, GPT2Tokenizer # initialize a tokenizer and a generator based on a pre-trained GPT2 model. # used to: # -encode the text provided by the user into tokens # -translate (decode) the output of the generator back to text tokenizer = GPT2Tokenizer.from_pretrained('gpt2') # used to generate new tokens based on the inputted text generator = GPT2LMHeadModel.from_pretrained( 'gpt2' ) يُقدِّم النص التالي كأساس يستند إليه الإصدار الثاني من المحوِّل التوليدي مُسبق التدريب (2-GPT): text = 'We had dinner at this restaurant yesterday. It is very close to my house. All my friends were there, we had a great time. The location is 186

المحولات
نموذج الاصدار الثاني من المحول التوليدي مسبق التدريب
187 وزارة التعليم Ministry of Education 2024-1446 excellent and the steaks were delicious. I will definitely return soon, highly recommended!' # encodes the given text into tokens encoded_text = tokenizer.encode(text, return_tensors='pt') # use the generator to generate more tokens. #do_sample=True prevents GPT-2 from just predicting the most likely word at every step. generated_tokens = generator.generate (encoded_text, generate max_length=200) #max number of new tokens to #decode the generates tokens to convert them to words #skip_special_tokens=True is used to avoid special tokens such as '>' or '-' characters. print(tokenizer.decode(generated_tokens[0], skip_special_tokens=True)) We had dinner at this restaurant yesterday. It is very close to my house. All my friends were there, we had a great time. The location is excellent and the steaks were delicious. I will definitely return soon, highly recommended! I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and I've been coming here for a while now and # use the generator to generate more tokens. #do_sample=True prevents GPT-2 from just predicting the most likely word at every step. generated_tokens = generator.generate(encoded_text, generate max_length=200, #max number of new tokens to do_sample=True) print(tokenizer.decode(generated_tokens[0], skip_special_tokens=True)) We had dinner at this restaurant yesterday. It is very close to my house. All my friends were there, we had a great time. The location is excellent and the steaks were delicious. I will definitely return soon, highly recommended! If you just found this place helpful. If you like to watch videos or go to the pool while you're there, go for it! Good service - I'm from Colorado and love to get in and out of this place. The food was amazing! Also, we were happy to see the waitstaff with their great hands - I went for dinner. I ordered a small side salad (with garlic on top), and had a slice of tuna instead. When I was eating, I was able to get up and eat my salad while waiting for my friend to pick up the plate, so I had a great time too. Staff was welcoming and accommodating. Parking is cheap in this neighborhood, and it is in the neighborhood that it needs to

نص يقدم كأساس يستند إليه الاصدار الثاني من المحول الوليدي مسبق التدريب
وزارة التعليم Ministry of Education 2024-1446 لل يحقق هذا مُخرجات أكثر تنوعًا ، مع الحفاظ على دقة وسلامة النص المولد، حيث يستخدم النص مفردات غنية وهو سلیم نحويًا . يسمح الإصدار الثاني من المحوِّل التوليدي مُسبق التدريب (2-GPT) بتخصيص المخرج بشكل أفضل. ذلك عند استخدام متغير temperature ( درجة الحرارة) الذي يسمح للنموذج بتقبل المزيد من المخاطر يتضح بل وأحيانًا اختيار بعض الكلمات الأقل احتمالا . القيم الأعلى لهذا المتغير تؤدي إلى نصوص أكثر تنوعا، مثل: # Generate tokens with higher diversity generated_tokens = generator.generate( encoded_text, max_length=200, do_sample=True, temperature=2.0) print(tokenizer.decode(generated_tokens[0], skip_special_tokens=True)) We had dinner at this restaurant yesterday. It is very close to my house. All my friends were there, we had a great time. The location is excellent and the steaks were delicious. I will definitely return soon, highly recommended! - Worth a 5 I thought a steak at a large butcher was the end story!! We were lucky. The price was cheap!! That night though as soon as dinner was on my turn that price cut completely out. At the tail area they only have french fries or kiwifet - no gravy they get a hard egg the other day too they call kawif at 3 PM it will be better this summer if I stay more late with friends. When asked it takes 2 or 3 weeks so far to cook that in this house. Once I found a place it was great. Everything I am waiting is just perfect as usual....great prices especially at one where a single bite would suffice or make more as this only runs on the regular hours ومع ذلك، إذا كانت درجة الحرارة مرتفعة للغاية، فإنّ النموذج سيتجاهل الإرشادات الأساسية التي تظهر في المدخل الأولي (Original seed) ويُولد مُخرَجًا أقل واقعية وليس له معنى: #Too high temperature leads to divergence in the meaning of the tokens generated_tokens = generator.generate( encoded_text, max_length=200, do_sample=True, temperature=4.0) print(tokenizer.decode(generated_tokens[0], skip_special_tokens=True)) We had dinner at this restaurant yesterday. It is very close to my house. All my friends were there, we had a great time. The location is excellent and the steaks were delicious. I will definitely return soon, highly recommended! It has the nicest ambagas of '98 that I like; most Mexican. And really nice steak house; amazing Mexican atmosphere to this very particular piece of house I just fell away before its due date, no surprise my 5yo one fell in right last July so it took forever at any number on it being 6 (with it taking two or sometimes 3 month), I really have found. comfort/affability on many more restaurants when ordering. If you try at it they tell ya all about 2 and three places will NOT come out before they close them/curry. Also at home i would leave everything until 1 hour but sometimes wait two nights waiting for 2+ then when 2 times you leave you wait in until 6 in such that it works to 188

يحقق هذا مخرجات أكثر تنوعاً مع الحفاظ على دقة وسلامة النص المولد
1 2 تمرينات حدد الجملة الصحيحة والجملة الخاطئة فيما يلي: .1. توليد اللغات الطبيعية المبني على تعلُّم الآلة يتطلب مجموعات كبيرة من بيانات التدريب والموارد الحسابية. 2 الفعل هو نوع من وسوم أقسام الكلام (POS). .3 في تحليل بناء الجمل لتوليد اللغات الطبيعية المبني على القوالب، يُستخدم التحليل بصورة منفصلة عن وسوم أقسام الكلام (POS). و 4. المجتمعات هي عناقيد العقد التي تُمثّل الكلمات المختلفة دلاليًا. 5. يصبح روبوت الدردشة أكثر ذكاءً كلما ازداد عدد مستويات الأسئلة والأجوبة المضافة إلى قاعدة المعرفة. قارن بين المنهجيات المختلفة لتوليد اللغات الطبيعية (NLG). 3 حدِّد ثلاث تطبيقات مختلفة لتوليد اللغات الطبيعية (NLG). صحيحة خاطئة 189 وزارة التعليم Ministry of Education 2024-1446

حدد الجملة الصحيحة والجملة الخاطئة فيما يلي: توليد اللغات الطبيعية المبني على تعلم الآلة يتطلب مجموعات كبيرة من بيانات التدريب والموارد الحسابية

قارن بين المنهجيات المختلفة لتوليد اللغات الطبيعية
حدد ثلاث تطبيقات مختلفة لتوليد اللغات الطبيعية
4 أكمل المقطع البرمجي التالي حتى تقبل الدالة ()build_graph مفردات مُحدَّدة من الكلمات ونموذج الكلمة إلى المتجه (Word Vec المدرب لرسم مُخطَّط ذي عُقدة واحدة لكل كلمة في المفردات المحددة. يجب أن يحتوي المخطط على حافة بين عُقدتين إذا كان تشابه نموذج الكلمة إلى المتَّجه (Word2Vec) أكبر من مستوى التشابه المعطى، ويجب ألا تكون هناك أوزان على الحواف. وزارة التعليم Ministry of Education 2024-1446 from import combinations #tool used to create combinations import networkx as nx # python library for processing graphs def build_graph(vocab:set, # set of unique words model_wv, # Word2Vec model similarity_threshold:float ): pairs=combinations(vocab, G=nx. # makes a new graph ) # gets all possible pairs of words in the vocabulary for w1, w2 in pairs: #for every pair of words w1,w2 sim=model_wv. if return G G. (w1,w2) (w1, w2)# gets the similarity between the two words 190

أكمل المقطع البرمجي التالي حتى تقبل الدالة build_graph() مفردات محددة من الكلمات ونموذج الكلمة الى المتجه
191 5 أكمل المقطع البرمجي التالي حتى تستخدم الدالة ()get_max_sim نموذج تمثيلات ترميز الجمل ثنائية الاتجاه من المحولات (SBERT) للمقارنة بين جُملة مُحدَّدة my_sentence وكل الجمل الواردة في قائمة أخرى من الجمل .. يجب أن تُعيد الدالة الجُملة ذات مؤشر التشابه الأعلى من L1 إلى my_sentence. وزارة التعليم Ministry of Education 2024-1446 from sentence_transformers import from model_sbert = util import combinations #tool used to create combinations def get_max_sim(L1, my_sentence): # embeds my_sentence my_embedding = model_sbert, # embeds the sentences from L2 L_embeddings = model_sbert. similarity_scores ('all-MiniLM-L6-v2') ([my_sentence], convert_to_tensor=True) (L, convert_to_tensor=True) .cos_sim( winner_index= np.argmax(similarity_scores[0]) return )

أكمل المقطع البرمجي التالي حتى تستخدم الدالة get_max_sim() نموذج تمثيلات ترميز الجمل ثنائية الاتجاه من المحولا