التعلم الموجه - الذكاء الاصطناعي - ثالث ثانوي
الجزء الأول
1. أساسيات الذكاء الاصطناعي
2. خوارزميات الذكاء الاصطناعي
3. معالجة اللغات الطبيعية
الجزء الثاني
4. التعرف على الصور
5. خوارزميات التحسين واتخاذ القرار
6. الذكاء الاصطناعي والمجتمع
 00:51
00:51



132 .3 معالجة اللغات الطبيعية سيتعلم الصـ لب في هذه الوحدة عملية تدريب شاملة لنموذج التعلم الموجه والتعلُّم غير الموجه لفهم المعنى الكامن في أجزاء النصوص. وكذلك سيتعلّم كيفية استخدام تعلُّم الآلة (Machine Learning - ML) في دعم التطبيقات ذات الصلة بمعالجة اللغات الطبيعية (Natural Language Processing (NLP). أهداف التعلم بنهاية هذه الوحدة سيكون الطالب قادرا على أن : > يُعرف التعلم الموجه. V V V V V يُدرِّب نموذج التعلُّم الموجه على فهم النص. يعرف التعلم غير الموجه. يُدرب نموذج التعلُّم غير الموجه على فهم النص. ينشئ روبوت دردشة بسيط. > يُنتج النصوص باستخدام تقنيات توليد اللغــات الطبيعية .(Natural Language Generation - NLG) الأدوات > مفكّرة جوبيتر (Jupyter Notebook) وزارة التعليم Ministry of Education 2024-1446

معالجة اللغات الطبيعية

الدرس الأول رابط الدرس الرقمي التعلُّم الموجّه استخدام التعلم الموجه لفهم النصوص Using Supervised Learning to Understand Text www.ien.edu.sa معالجة اللغات الطبيعية (Natural Language Processing - (NLP) هي إحدى مجالات الذكاء الاصطناعي Artificial Intelligence - Al) التي تركّز على تمكين أجهزة الحاسب لتصبح قادرة على فهم اللغات البشرية، وتفسيرها، وإنتاجها. حيث تُعنى معالجة اللغات الطبيعية بعدد من المهام، مثل: تصنيف النصوص، وتحليل المشاعر، والترجمة الآلية، والإجابة الأسئلة. سيركز هذا الدرس بشكل خاص على كيفية استخدام التعلم الموجّه الذي يُعدُّ أحد الأنواع الرئيسة لتعلم الآلة (Machine Learning - ML في تحقيق الفهم والتنبؤ التلقائي لخصائص النصوص. على . لقد تعلمت في الوحدة الأولى أن الذكاء الاصطناعي هو مصطلح يشمل كلا من تعلُّم الآلة والتعلم العميق، كما يتضح في الشكل 3.1، فالذكاء الاصطناعي هو ذلك المجال الواسع من علوم الحاسب الذي يُعني بابتكار آلات ذكية، بينما تعلَّم الآلة هو أحد فروع الذكاء الاصطناعي الذي يركّز على تصميم الخوارزميات وبناء النماذج التي تُمكّن الآلة من التعلم من البيانات دون الحاجة إلى برمجتها بشكل صريح. الذكاء الاصطناعي تعلم الآلة التعلُّم العميق التعلم العميق (Deep Learning) : التعلُّم العميق هو أحد أنواع تعلم الآلة الذي يستخدم الشبكات العصبية العميقة للتعلَّم تلقائيًا من مجموعات كبيرة من البيانات، فهو يسمح لأجهزة الحاسب بالتعرّف على الأنماط واتخاذ القرارات بطريقة تحاكي الإنسان، عبر تصميم نماذج معقدة من البيانات. شكل 31 فروع الذكاء الاصطناعي تعلم الآلة Machine Learning تعِلُّم الآلة هو أحد فروع الذكاء الاصطناعي المعني بتطوير الخوارزميات التي تُمكِّن أجهزة الحاسب من التعلُّم من البيانات المدخلة، بدلًا من اتباع التعليمات البرمجية الصريحة، فهو يعمل على تدريب نماذج الحاسب للتعرف على الأنماط والقيام بالتنبؤات وفقًا للبيانات المدخلة مما يسمح للنموذج بتحسين الدقة مع مرور الوقت، وكذلك يتيح للآلة أداء مهام متعددة، مثل: التصنيف، والانحدار، والتجميع، وتقديم التوصيات دون الحاجة إلى برمجة الآلة بشكل صريح للقيام بكل مُهمَّة على حدة. يمكن تصنيف تعلُّم الآلة إلى ثلاثة أنواع رئيسة: التعلم الموجه (Supervised Learning) هو نوع من تعلم الآلة تتعلم فيه الخوارزمية من بيانات تدريب معنونة (Labelled ) بهدف القيام بالتنبؤات حول بيانات جديدة غير موجودة في مجموعة التدريب أو الاختبار كما هو موضح في الشكل 3.2 ، ومن الأمثلة عليه: • تصنيف الصور (ication ، مثل : التعرف على الكائنات في الصور. كشف الاحتيال (Fraud Detection ، مثل تحديد المعاملات المالية المشبوهة. تصفية البريد الإلكتروني العشوائي (Spam Filtering مثل تحديد رسائل البريد الإلكتروني غير المرغوب فيها . ، 133 وزارة التعليم Ministry of Education 2024-1446

استخدام التعلم الموجه لفهم النصوص: معالجة النصوص الطبيعية
تعلم الآلة
التعلم الموجه
التعلم غير الموجه (Unsupervised Learning) هو نوع من تعلم الآلة تعمل فيه الخوارزمية بموجب بيانات غير معنونة (Unlabeled) في محاولة لإيجاد الأنماط والعلاقات بين والعلاقات بين البيانات، ومن الأمثلة عليه: الكشف عن الاختلاف (Anomaly Detection)، مثل: تحديد الأنماط غير العادية في البيانات. التجميع (Clustering) ، مثل تجميع البيانات ذات الخصائص المتشابهة. تقليص الأبعاد (Dimensionality Reduction)، مثل: اختيار الأبعاد المستخدمة للحد من تعقيد البيانات. الاختبار المخرج المتوقع مجموعة بيانات التعلم المعزز (Reinforcement Learning) هو نوع من تعلم الآلة تتفاعل فيه الآلة مع البيئة المحيطة وتتعلّم عبر المحاولة والخطأ أو تلقي المكافأة والعقاب، ومن الأمثلة عليه: • لعب الألعاب، مثل: لعبة الشطرنج أو لعبة قو (GO). الروبوتية، مثل: تعليم الروبوت كيف يتنقل في البيئة المحيطة به. • تخصيص الموارد، مثل: تحسين استخدام الموارد في شبكة ما. جدول 3.1 يلخص مزايا أنواع تعلم الآلة وعيوبها. جدول 31 مزايا أنواع تعلم الآلة، وعيوبها التعلم الموجه المزايا Я مجموع عة بيانات التدريب المخرج المطلوب A هـ A النموذج الخوارزمية 0000 0000 0000 شكل 3.2: تمثيل التعلم الموجه العيوب أثبت كفاءة وفعالية كبيرة ويستخدم على نطاق واسع. يتطلب بيانات ،معنونة، والتى قد تكون مرتفعة التكلفة. سهل الفهم والتطبيق. استخدامه على المُهمَّة التي تم تدريبه عليها ، وقد يقتصر . يُمكنه التعامل مع البيانات الخطية وغير الخطية على لا يمكنه إعطاء التنبؤ الصحيح للبيانات الجديدة. . يصعب تكيفه مع المشكلات الأخرى في حالات النماذج حد سواء. التعلم غير الموجه و • لا يتطلب بيانات معنونة، مما يجعله أكثر مرونة. يُمكنه اكتشاف الأنماط الخفية في البيانات. . يُمكنه التعامل مع البيانات الضخمة والمعقدة. التعلم المعزّز و المعقدة جدا. أصعب من التعلُّم الموجه من حيث الفهم والتفسير. يقتصر على التحليل الاستكشافي، وقد لا يناسب عمليات صنع القرار. • يصعب تكيفه مع المشكلات الأخرى في حالات النماذج المعقدة جدا. لل تل • يتّسم بالمرونة، ويُمكنه التعامل مع البيئات المعقدة . أكثر تعقيدا من التعلم الموجه وغير الموجه. والمتغيرة باستمرار. • صعوبة تصميم نظم مكافآت تُحدد السلوك المطلوب • قد يتطلب مجموعات كبيرة من بيانات التدريب والموارد الحسابية. . يمكنه التعلم من التجارب السابقة وتحسين الكفاءة مع بشكل دقيق. مرور الوقت. . يتناسب مع عمليات صُنع القرار مثل لعب الألعاب والروبوتية. وزارة التعليم Ministry of Education 2024-1446 134

التعلم غير الموجه
التعلم المعزز
مزايا أنواع تعلم الآلة وعيوبها
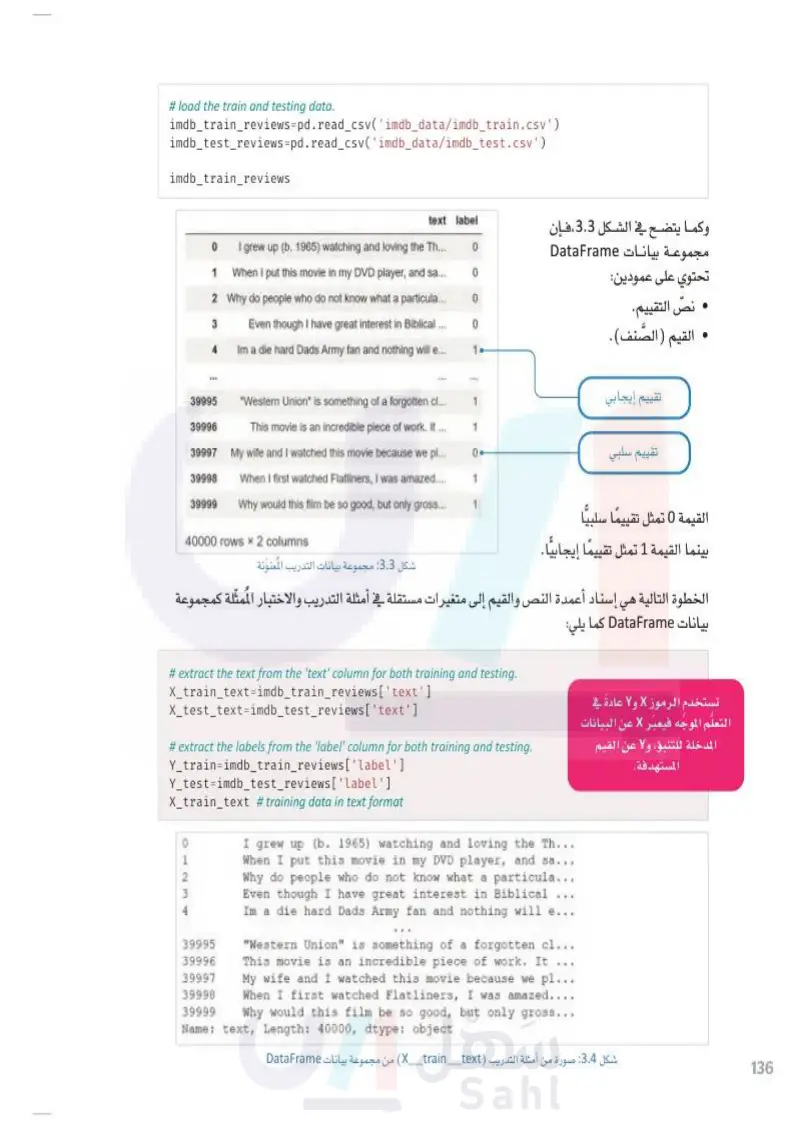
135 التعلم الموجه Supervised Learning (Supervised Learning) لک التعلُّم الموجه هو أحد أنواع تعلُّم الآلة الذي يعتمد على استخدام البيانات التعلم الموجه المعنونة لتدريب الخوارزميات للقيام بالتنبؤات. يتم تدريب الخوارزمية على مجموعة من البيانات المعنونة ثم اختبارها على مجموعة بيانات جديدة لم تكن جزءًا من بيانات التدريب. يُستخدَم التعلُّم الموجه عادةً في معالجة ستستخدم في التعلم الموجه مجموعات اللغات الطبيعية للقيام بمهام مثل: تصنيف النصوص، وتحليل المشاعر، البيانات المعنونة والمنظمة بشكل يدوي والتعرف على الكيانات المسماة (Named Entity Recognition - NER). لتدريب خوارزميات الحاسب على التنبؤ في هذه المهام يتم تدريب الخوارزمية على مجموعة من البيانات المعنونة، بالقيم الجديدة. حيث يتم إدراج كل مثال تحت عنوان التصنيف المناسب أو المشاعر المناسبة. يُطلق على عملية التعلُّم الموجَّه اسم الانحدار (Regression) عندمـا تكون القيم التي تتنبأ بها الآلة رقميّة، بينما يطلق عليها اسم التصنيف (Classification) عندما تكون القيم متقطعه. الانحدار على سبيل المثال، قد يُستخدم الانحدار في التنبؤ بسعر بيع المنزل وفقًا لمساحته، وموقعه، وعدد غرف النوم فيه. كما يمكن استخدامه في التنبؤ بحجم الطلب على أحد المنتجات استنادًا إلى بيانات المبيعات التاريخية وحجم الإنفاق الإعلاني. وفي مجال معالجة اللغات الطبيعية، يستخدم الانحدار النصوص المدخلة المتوفرة للتنبؤ بتقييم الجمهور للفيلم أو مدى التفاعل مع المنشورات الخاصة به على وسائل التواصل الاجتماعي. التصنيف من ناحية أخرى، يُستخدم التصنيف في التطبيقات مثل: تشخيص الحالات الطبية وفقًا للأعراض ونتائج الفحوصات. وعندما يتعلق الأمر بفهم النصوص ، يمكن استخدام التعلُّم الموجّه في تصنيف النصوص المدخلة إلى فئات أو عناوين أو التنبؤ بها بناءً على الكلمات أو العبارات الموجودة في المستند. على سبيل المثال، يمكن تدريب نموذج التعلم الموجه لتصنيف رسائل البريد الإلكتروني إلى رسائل مزعجة أو غير مزعجة وفقًا للكلمات أو العبارات المستخدمة في رسالة البريد الإلكتروني. ويُعدّ تصنيف المشاعر أحد التطبيقات الشهيرة كذلك، حيث يمكن التنبؤ بالانطباع العام حول مستند ما سواء كان سلبيًّا أم إيجابيًّا. وسَيُستخدم هذا التطبيق كمثال عملي في هذه الوحدة، لشرح كل خطوات عملية بناء واستخدام نموذج التعلُّم الموجه بشكل شامل من بداية رحلة التعلم حتى نهايتها. لگ في هذه الوحدة ستستخدم مجموعة بيانات من مراجعات الأفلام على موقع IMDb.com الشهير. ستجد البيانات مُقسمه إلى مجموعتين؛ الأولى ستستخدم لتدريب النموذج، والثانية لاختبار أداء النموذج. في البداية لابد أن تُحمّل البيانات إلى DataFrame ، لذا عليك استخدام مكتبة بانداس بايثون (Panda Python) والتي استخدمتها سابقًا. مكتبة بانداس هي إحدى الأدوات الشهيرة التي تُستخدم للتعامل مع جداول البيانات. التعليمات البرمجية التالية ستقوم باستيراد المكتبة إلى البرنامج، ثم تحميل مجموعتي البيانات: وزارة التعليم Ministry of Education 2024-1446 %%capture # capture is used to suppress the installation output. # install the pandas library, if it is missing. !pip install pandas • import pandas as pd مكتبة بانداس هي مكتبة شهيرة تُستخدم لقراءة ومعالجة البيانات الشبيهة بجداول البيانات.

التعلم الموجه
الانحدار
التصنيف
136 # load the train and testing data. imdb_train_reviews = pd.read_csv('imdb_data/imdb_train.csv') imdb_test_reviews = pd.read_csv('imdb_data/imdb_test.csv') imdb_train_reviews وكما يتضح في الشكل 3.3 ، فإن مجموعة بيانات DataFrame تحتوي على عمودين: نص التقييم. • القيم (الصنف). text label 0 I grew up (b. 1965) watching and loving the Th... 0 1 When I put this movie in my DVD player, and sa... 2 Why do people who do not know what a particula... 0 3 Even though I have great interest in Biblical ... 0 4 Im a die hard Dads Army fan and nothing will e... 1 تقييم إيجابي تقييم سلبي القيمة 0 تمثل تقييما سلبيا لگا بينما القيمة 1 تمثل تقييماً إيجابيًّا 39995 "Western Union" is something of a forgotten cl... 1 39996 39997 39998 39999 This movie is an incredible piece of work. It... My wife and I watched this movie because we pl... When I first watched Flatliners, I was amazed.... Why would this film be so good, but only gross... 1 0 1 1 40000 rows x 2 columns شكل 3.3 مجموعة بيانات التدريب المعنونة الخطوة التالية هي إسناد أعمدة النص والقيم إلى متغيرات مستقلة في أمثلة التدريب والاختبار الممثلة كمجموعة بيانات DataFrame كما يلي: يُستخدم الرمزان X و Y عادةً في التعلم الموجه فيعبر X عن البيانات المدخلة للتنبؤ، ولا عن القيم المستهدفة. # extract the text from the 'text' column for both training and testing. X_train_text=imdb_train_reviews['text'] X_test_text=imdb_test_reviews['text'] # extract the labels from the 'label' column for both training and testing. Y_train=imdb_train_reviews['label'] Y_test=imdb_test_reviews['label'] X_train_text # training data in text format 0 1 234 39995 39996 39997 39998 39999 I grew up (b. 1965) watching and loving the Th... When I put this movie in my DVD player, and sa. Why do people who do not know what a particula... Even though I have great interest in Biblical Im a die hard Dads Army fan and nothing will e... "Western Union" is something of a forgotten cl... This movie is an incredible piece of work. It My wife and I watched this movie because we pl... When I first watched Flatliners, I was amazed.... Why would this film be so good, but only gross... Name: text, Length: 40000, dtype: object _X)_train) من مجموعة بيانات DataFrame شكل 3.4 صورة من أمثلة التدريب text وزارة التعليم Ministry of Education 2024-1446

مجموعات بيانات تحتوي على عمودين: نص التقييم
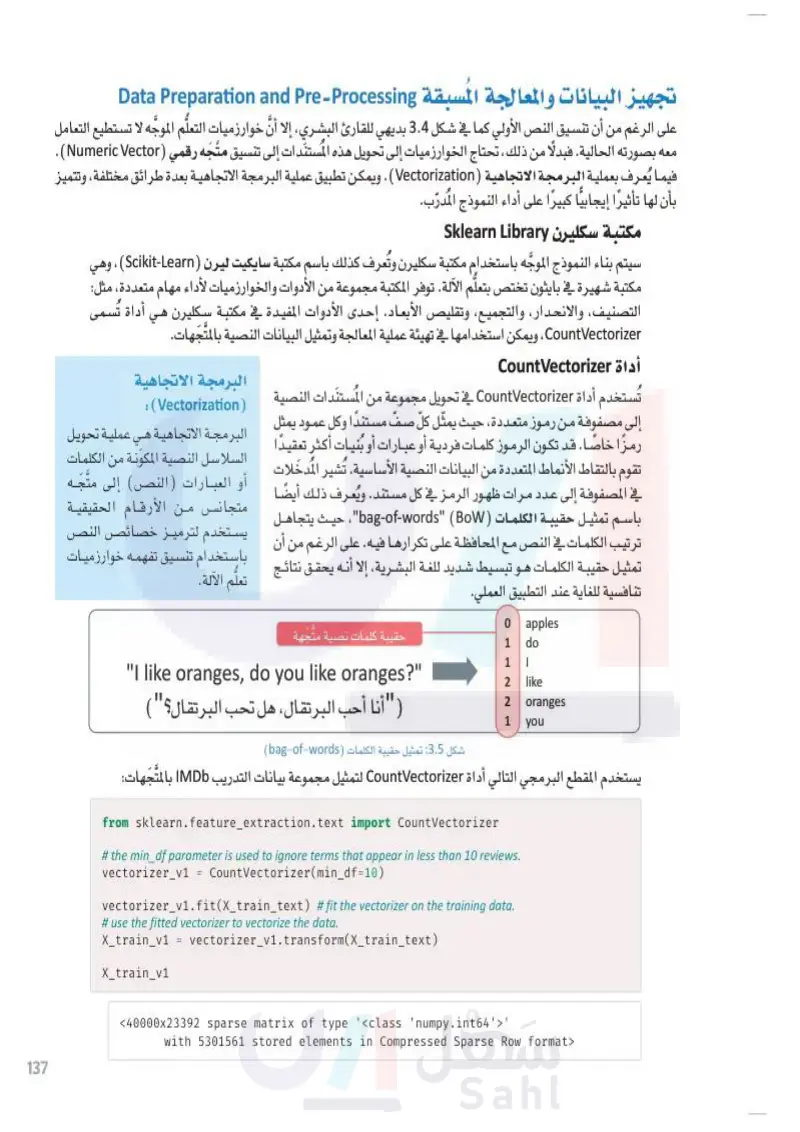
لل تجهيز البيانات والمعالجة المسبقة Data Preparation and Pre-Processing على الرغم من أن تنسيق النص الأولي كما في الشكل 3.4 بديهي للقارئ البشري، إلا أنَّ خوارزميات التعلُّم الموجه لا تستطيع التعامل معه بصورته الحالية. فبدلا من ذلك، تحتاج الخوارزميات إلى تحويل هذه المستندات إلى تنسيق متَّجَه رقمي (Numeric Vector) . فيما يُعرف بعملية البرمجة الاتجاهية (Vectorization) . ويمكن تطبيق عملية البرمجة الاتجاهية بعدة طرائق مختلفة، وتتميز بأن لها تأثيرًا إيجابيًا كبيرًا على أداء النموذج المدرّب. مكتبة سكليرن Sklearn Library سيتم بناء النموذج الموجه باستخدام مكتبة سكليرن وتُعرف كذلك باسم مكتبة سايكيت ليرن (Scikit-Learn) ، وهي مكتبة شهيرة في البايثون تختص بتعلُّم الآلة. توفر المكتبة مجموعة من الأدوات والخوارزميات لأداء مهام متعددة، مثل: التصنيف، والانحدار، والتجميع، وتقليص الأبعاد. إحدى الأدوات المفيدة في مكتبة سكليرن هي أداة تُسمى CountVectorizer ، ويمكن استخدامها في تهيئة عملية المعالجة وتمثيل البيانات النصية بالمتجهات. أداة CountVectorizer البرمجة الاتجاهية تُستخدم أداة CountVectorizer في تحويل مجموعة من المستندات النصية (Vectorization) إلى مصفوفة من رموز متعددة، حيث يمثل كلّ صفّ مستندًا وكل عمود يمثل رمزًا خاصًا . قد تكون الرموز كلمات فردية أو عبارات أو بنيات أكثر تعقيدًا البرمجة الاتجاهية هي عملية تحويل تقوم بالتقاط الأنماط المتعددة من البيانات النصية الأساسية. تُشير المدخلات السلاسل النصية المكونة من الكلمات في المصفوفة إلى عدد مرات ظهور الرمز في كل مستند. ويُعرف ذلك أيضًا العبارات (النص) إلى متجه باسم تمثيل حقيبة الكلمات (bag-of-words (BW"، حيث يتجاهل متجانس من الأرقام الحقيقية يستخدم لترميز خصائص النص ترتيب الكلمات في النص مع المحافظة على تكرارها فيه . على الرغم من أن تمثيل حقيبة الكلمات هو تبسيط شديد للغة البشرية، إلا أنه يحقق نتائج باستخدام تنسيق تفهمه خوارزميات تنافسية للغاية عند التطبيق العملي. تعلم الآلة. 137 وزارة التعليم Ministry of Education 2024-1446 حقيبة كلمات نصية متجهة "I like oranges, do you like oranges?" ( " أنا أحب البرتقال، هل تحب البرتقال؟ ") 0 | apples 1 do 1 2 like 2 oranges 1 you شكل 3.5 تمثيل حقيبة الكلمات bag-of-words) يستخدم المقطع البرمجي التالي أداة CountVectorizer لتمثيل مجموعة بيانات التدريب IMDb بالمتجهات: from sklearn.feature_extraction.text import CountVectorizer # the min_df parameter is used to ignore terms that appear in less than 10 reviews. vectorizer_v1 = CountVectorizer(min_df=10) vectorizer_v1.fit(X_train_text) #fit the vectorizer on the training data. # use the fitted vectorizer to vectorize the data. X_train_v1 = vectorizer_v1.transform(x_train_text) X_train_v1 <40000x23392 sparse matrix of type '<class 'numpy.int64'>' with 5301561 stored elements in Compressed Sparse Row format>

تجهيز البيانات والمعالجة المسبقة: مكتبة سكليرن
أداة countVectorizer
# expand the sparse data into a sparse matrix format, where each column represents a different word. X_train_v1_dense=pd.DataFrame(X_train_v1.toarray(), X_train_v1_dense columns=vectorizer_v1.get_feature_names_out()) : : 00 000 007 01 02 04 05 06 07 08 ZOO zoom zooming zooms zorro zu Zucco zucker zulu über 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ... 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ... 3 0 0 o 0 o 0 0 4 0 0 0 0 0 0 o o o o o 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 : : : : 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 : : : : : : 39995 0 0 0 0 0 0 0 0 0 : : : : 39996 0 0 0 0 0 0 0 0 0 39997 0 0 0 0 0 0 0 0 0 0 39998 0 0 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 ... : 39999 0 2 0 0 0 0 0 0 0 0 40000 rows x 23392 columns و شكل 3.6 تمثيل مجموعة بيانات التدريب بالمتجهات ً عبر هذا التنسيق الكثيف ( Dense) للمصفوفة عن 40,000 تقييم ومراجعة في بيانات التدريب. تحتوي المصفوفة على عمود لكل كلمة تظهر في 10 مراجعات على الأقل منفذة بواسطة المتغير min_df). كما يتضح بالأعلى، ينتج عن ذلك 23,392 عمودًا ، مرتبة في ترتيب أبجدي رقمي. يُعبِّر مُدخل المصفوفة في الموضع [ii] عن عدد المرات التي تظهر فيها كلمة في المراجعة .أ. وعلى الرغم من إمكانية استخدام هذه المصفوفة مباشرةً من قبل خوارزمية التعلم الموجّه، إلا أنها غير فعّالة من حيث استخدام الذاكرة والسبب في ذلك أن الغالبية العظمى من المدخلات في هذه المصفوفة تساوي 0 . وهذا يحدث لأن نسبة ضئيلة جدًا فقط من بين 23,392 كلمة محتملة ستظهر فعليًا في كل مراجعة ولمعالجة هذا القصور ، تخزن أداة CountVectorizer البيانات الممثلة بالمتجهات في مصفوفة متباعدة، حيث تحتفظ فقط بالمدخلات غير الصفرية في كل عمود . يستخدم المقطع البرمجي الكائنات في لغة البايثون (Python) بالبايت (Bytes) لتوضيح بالأسفل الدالة ( )getsizeof التي تحدد حجم مدى التوفير في الذاكرة عند استخدام المصفوفة المتباعدة لبيانات IMDb .0 from sys import getsizeof print('\nMegaBytes of RAM memory used by the raw text format:', getsizeof(X_train_text)/1000000) print('\nMegaBytes of RAM memory used by the dense matrix format:', getsizeof(X_train_v1_dense)/1000000) print('\nMegaBytes of RAM memory used by the sparse format:', getsizeof(x_train_v1)/1000000) MegaBytes of RAM memory used by the raw text format: 54.864133 MegaBytes of RAM memory used by the dense matrix format: 7485.440144 MegaBytes of RAM memory used by the sparse format: 4.8e-05 وزارة التعليم Ministry of Education 2024-1446 138

مقطع برمجي لتمثيل مجموعات بيانات التدريب IMDb بالمتجهات 1
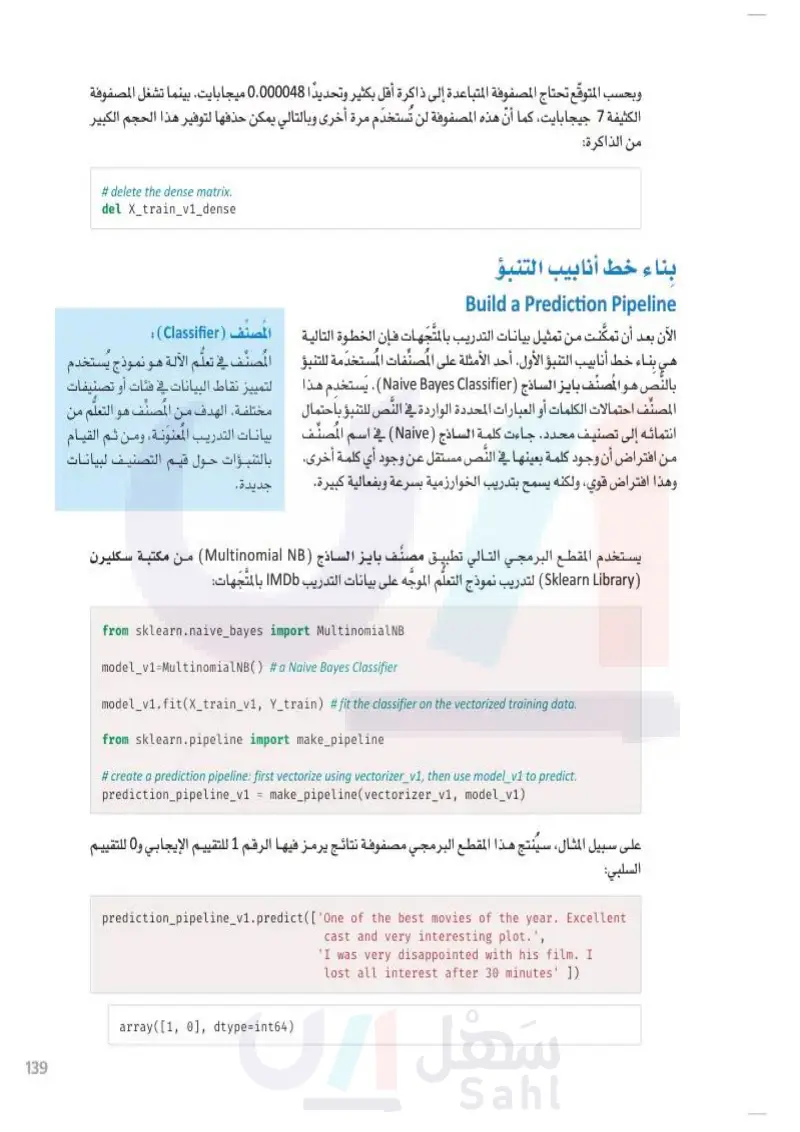
139 وبحسب المتوقع تحتاج المصفوفة المتباعدة إلى ذاكرة أقل بكثير وتحديدًا 0.000048 ميجابايت، بينما تشغل المصفوفة الكثيفة 7 جيجابايت، كما أنّ هذه المصفوفة لن تُستخدم مرة أخرى وبالتالي يمكن حذفها لتوفير هذا الحجم الكبير من الذاكرة # delete the dense matrix. del X_train_v1_dense بناء خط ء خط أنابيب التنبؤ Building a Prediction Pipeline الآن بعد أن تمكَّنت من تمثيل بيانات التدريب بالمتَّجَهات فإن الخطوة التالية المصنف (Classifier) : هي بناء خط أنابيب التنبؤ الأول. وللقيام بذلك، ستستخدم نوعًا من المصنفات الصنف في تعلم الآلة هو نموذج يُستخدم مُصنِّف يسمى بايز الساذج (Naive Bayes Classifier)، حيث يستخدم لتمييز نقاط البيانات في فئات أو تصنيفات هذا المصنِّف احتمالات الكلمات أو العبارات المحددة الواردة في النّص للتنبؤ مختلفة. الهدف من المصنِّف هو التعلم من باحتمال انتمائه إلى تصنيف محدد. جاءت كلمة الساذج (Naive) في اسم بيانات التدريب المعنونة، ومن ثَمَّ القيام المُصنِّف من افتراض أن وجود كلمة بعينها في النَّص مستقل عن وجود أي كلمة بالتنبؤات حول قيم التصنيف لبيانات أخرى. وهذا افتراض قوي، ولكنه يسمح بتدريب الخوارزمية بسرعة وبفعالية كبيرة. لک جديدة. يستخدم المقطع البرمجي التالي تطبيق مُصنّف بايز الساذج ( Multinomial) من مكتبة سكليرن (Sklearn Library) لتدريب نموذج التعلَّم الموجه على بيانات التدريب IMDb بالمتجهات: وزارة التعليم Ministry of Education 2024-1446 from sklearn.naive_bayes import MultinomialNB model_v1=MultinomialNB() # a Naive Bayes Classifier model_v1.fit(X_train_v1, Y_train) #fit the classifier on the vectorized training data. from sklearn.pipeline import make_pipeline # create a prediction pipeline: first vectorize using vectorizer_v1, then use model_v1 to predict. prediction_pipeline_v1 = make_pipeline(vectorizer_v1, model_v1) على سبيل المثال، سيُنتج هذا المقطع البرمجي مصفوفة نتائج يرمز فيها الرقم 1 للتقييم الإيجابي و0 للتقييم السلبي: prediction_pipeline_v1.predict(['One of the best movies of the year. Excellent cast and very interesting plot.', 'I was very disappointed with his film. I lost all interest after 30 minutes' ]) array([1, 0], dtype=int64)

وبحسب المتوقع تحتاج المصفوفة المتباعدة إلى ذاكرة أقل بكثير وتحديدا 0.000048 ميجابايت
بناء خط أنابيب التنبؤ
وزارة التعليم Ministry of Education 2024-1446 يتنبأ خط الأنابيب بشكل صحيح بالقيمة الإيجابية للتقييم الأول والقيمة السلبية للتقييم الثاني. يُمكن استخدام الدالة المضمّنة (predict_proba لتحديد جميع الاحتمالات التي يقوم خط الأنابيب بتخصـ خط الأنابيب بتخصيصها لكل واحدة من القيمتين المحتملتين. العنصر الأول هو احتمال تعيين 0 والعنصر الثاني هو احتمال تعيين 1: prediction_pipeline_v1.predict_proba(['One of the best movies of the year. EX cellent cast and very interesting plot.', 'I was very disappointed with his film. I lost all interest after 30 minutes' ]) array([[0.08310769, 0.91689231], [0.83173475, 0.16826525]]) 16.8% التقييم الثاني 8.3% التقييم الأول النموذج يؤكد بنسبة 8.3% أن التقييم الأول سلبي، بينما يؤكد بنسبة %91.7 أنه إيجابي. وبالمثل، يؤكد النموذج بنسبة 83.1% أن التقييم الثاني سلبي، بينما يؤكد بنسبة %16.8 أنه إيجابي. 91.6% إيجابي سلبي 83.1% شكل :3.7 مُخطَّطان دائريان يوضّحان النسب المئوية للتقييمين الخطوة التالية هي اختبار دقة خط الأنابيب الجديد في تصنيف التقييمات في مجموعة بيانات اختبار IMDb. المخرج هو مصفوفة تشمل جميع قيم نتائج تصنيف التقييمات الواردة في بيانات الاختبار: # use the pipeline to predict the labels of the testing data. predictions_v1 = prediction_pipeline_v1.predict(x_test_text) # vectorize the text data, then predict. predictions_v1 array([0, 0, 0, ..., 0, 0, 0, dtype=int64) توفر لغة البايثون العديد من الأدوات لتحليل وتصوير نتائج خطوط أنابيب التصنيف. تشمل الأمثلة دالة ( )accuracy_score من مكتبة سكليرن وتمثيل مصفوفة الدقة (Confusion Matrix من مكتبة سايكيت بلوت (Scikit-plot)، وهناك مقاييس تقييم أخرى مثل: الدقة، والاستدعاء ، والنوعية، والحساسية، ومقياس درجة F1، وفقًا لحالة الاستخدام التي يمكن حسابها من مصفوفة الدقة. المخرج التالي هو تقريب دقيق لدرجة التنبؤ: from sklearn.metrics import accuracy_score accuracy_score (Y_test, predictions_v1) # get the achieved accuracy. 0.8468 140

يتنبأ خط الأنابيب بشكل صحيح بالقيمة الايجابية والسلبية للتقييمين الأول والثاني على التوالي
القيم الحقيقية. %%capture !pip install scikit-plot; # install the scikit-plot library, if it is missing. import scikitplot%3B #import the library class_names=['neg','pos'] # pick intuitive names for the O and 1 labels. # plot the confusion matrix. scikitplot.metrics.plot_confusion_matrix( [class_names[i] for i in Y_test], [class_names[i] for i in predictions_v1], title="Confusion Matrix", # title to use cmap="Purples", # color palette to use figsize=(5,5) # figure size ); القيم المتوقعة. تحتوي مصفوفة الدقة على عدد التصنيفات الحقيقية مقابل المتوقعة. في مُهمَّة التصنيف الثنائية (مثل: مسألة احتواء قيمتين، الموجودة في مُهمَّة IMDb) ، ستحتوي مصفوفة الدقة على أربع خلايا: التنبؤات السالبة الصحيحة (أعلى اليسار) عدد المرات التي تنبأ فيها المصنّف بالحالات السالبة بشكل صحيح. التنبؤات السالبة الخاطئة (أعلى اليمين): عدد المرات التي تنبأ فيها المصنّف بالحالات السالبة بشكل خاطئ. التنبؤات الموجبة الخاطئة أسفل اليسار) عدد المرات التي تنبأ فيها المصنّف بالحالات الموجبة بشكل خاطئ. التنبؤات الموجبة الصحيحة (أسفل اليمين): عدد المرات التي تنبأ فيها المصنّف بالحالات الموجبة بشكل صحيح. Confusion Matrix 2000 -1750 neg 2164 331 1500 1250 1000 pos 435 2070 750 500 neg pos Predicted label شكل 3.8: نتائج مصفوفة الدقة بتطبيق مصنف بايز الساذج على بيانات الاختبار باستخدام مجموعة بيانات IMDb تُظهر النتائج أنه على الرغم من أن خط الأنابيب الأول يحقق دقة تنافسية تصل إلى %84.68، إلا أنه لا يزال يُخطئ في تصنيف مئات التقييمات. فهناك 331 تنبّوا غير صحيح في الربع الأيمن العلوي و 435 تنبّوا غير صحيح في الربع الأيسر السفلي، بإجمالي 766 تنبوا غير صحيح. الخطوة الأولى نحو تحسين الأداء هي دراسة سلوك خط أنابيب التنبؤ، لمعرفة كيف يقوم بمعالجة النصّ الدقة الدقة ( Accuracy نسبة التنبؤات الصحيحة إلى إجمالي عدد التنبؤات. ( التنبؤات الموجبة الصحيحة + التنبؤات السالبة الصحيحة) الدقة : هي = True label التنبؤات الموجبة الصحيحة + التنبؤات السالبة الصحيحة + التنبؤات الموجبة الخاطئة + التنبؤات السالبة الخاطئة ) وفهمه. 141 وزارة التعليم Ministry of Education 2024-1446

تحتوي مصفوفة الدقة على عدد التصنيفات الحقيقية مقابل المتوقعة
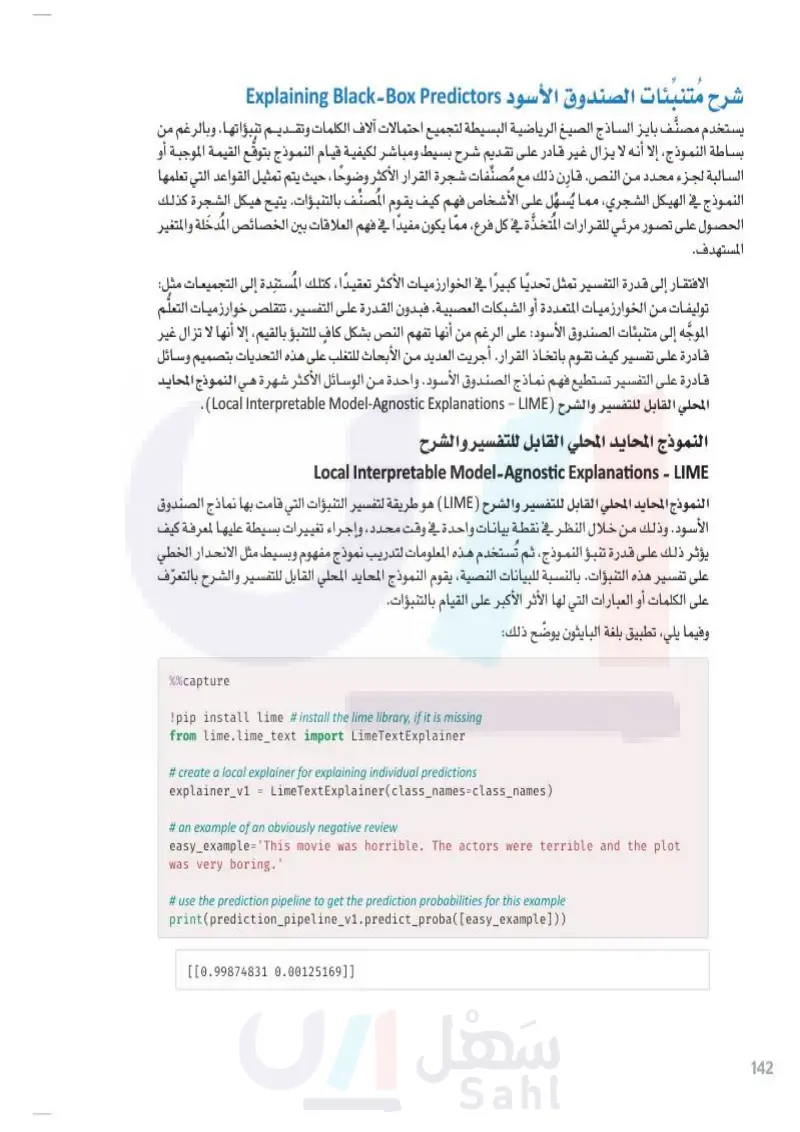
وزارة التعليم Ministry of Education 2024-1446 شرح متنبئات الصندوق الأسود Explaining Black-Box Predictors يستخدم مصنف بايز الساذج الصيغ الرياضية البسيطة لتجميع احتمالات آلاف الكلمات وتقــديــم تنبؤاتها. وبالرغم من بساطة النموذج ، إلا أنه لا يزال غير قادر على تقديم شرح بسيط ومباشر لكيفية قيام النموذج بتوقع القيمة الموجبة أو السالبة لجزء محدد من النص. قارن ذلك مع مُصنِّفات شجرة القرار الأكثر وضوحا، حيث يتم تمثيل القواعد التي تعلمها النموذج في الهيكل الشجري، مما يُسهل على الأشخاص فهم كيف يقوم المصنف بالتنبؤات. يتيح هيكل الشجرة كذلك الحصول على تصور مرئي للقرارات المتخذة في كل فرع، ممّا يكون مفيداً في فهم العلاقات بين الخصائص المدخلة والمتغير المستهدف. الافتقار إلى قدرة التفسير تمثل تحديا كبيرا في الخوارزميات الأكثر تعقيدًا، كتلك المستندة إلى التجميعات مثل: توليفات من الخوارزميات المتعددة أو الشبكات العصبية. فبدون القدرة على التفسير، تتقلص خوارزميات التعلم الموجه إلى متنبئات الصندوق الأسود على الرغم من أنها تفهم النص بشكل كافٍ للتنبؤ بالقيم، إلا أنها لا تزال غير قادرة على تفسير كيف تقوم باتخاذ القرار. أجريت العديد من الأبحاث للتغلب على هذه التحديات بتصميم وسائل قادرة على التفسير تستطيع فهم نماذج الصندوق الأسود واحدة من الوسائل الأكثر شهرة هي النموذج المحايد المحلي القابل للتفسير والشرح Local Interpretable Model-Agnostic Explanations - ME). النموذج المحايد المحلي القابل للتفسير والشرح · Local Interpretable Model-Agnostic Explanations - LIME النموذج المحايد المحلي القابل للتفسير والشرح (IME) هو طريقة لتفسير التنبؤات التي قامت بها نماذج الصندوق الأسود . وذلك من خلال النظر في نقطة بيانات واحدة في وقت محدد، وإجراء تغييرات بسيطة عليها لمعرفة كيف يؤثر ذلك على قدرة تنبؤ النموذج، ثم تُستخدم هذه المعلومات لتدريب نموذج مفهوم وبسيط مثل الانحدار الخطي على تفسير هذه التنبؤات. بالنسبة للبيانات النصية، يقوم النموذج المحايد المحلي القابل للتفسير والشرح بالتعرّف على الكلمات أو العبارات التي لها الأثر الأكبر على القيام بالتنبؤات. وفيما يلي، تطبيق بلغة البايثون يوضّح ذلك: %%capture !pip install lime # install the lime library, if it is missing from lime.lime_text import LimeTextExplainer # create a local explainer for explaining individual predictions explainer_v1 = LimeTextExplainer(class_names=class_names) # an example of an obviously negative review easy_example='This movie was horrible. The actors were terrible and the plot was very boring.' # use the prediction pipeline to get the prediction probabilities for this example print(prediction_pipeline_v1.predict_proba([easy_example])) [[0.99874831 0.00125169]] 142

شرح متنبئات الصندوق الأسود
النموذج المحايد المحلي القابل للتفسير والشرح
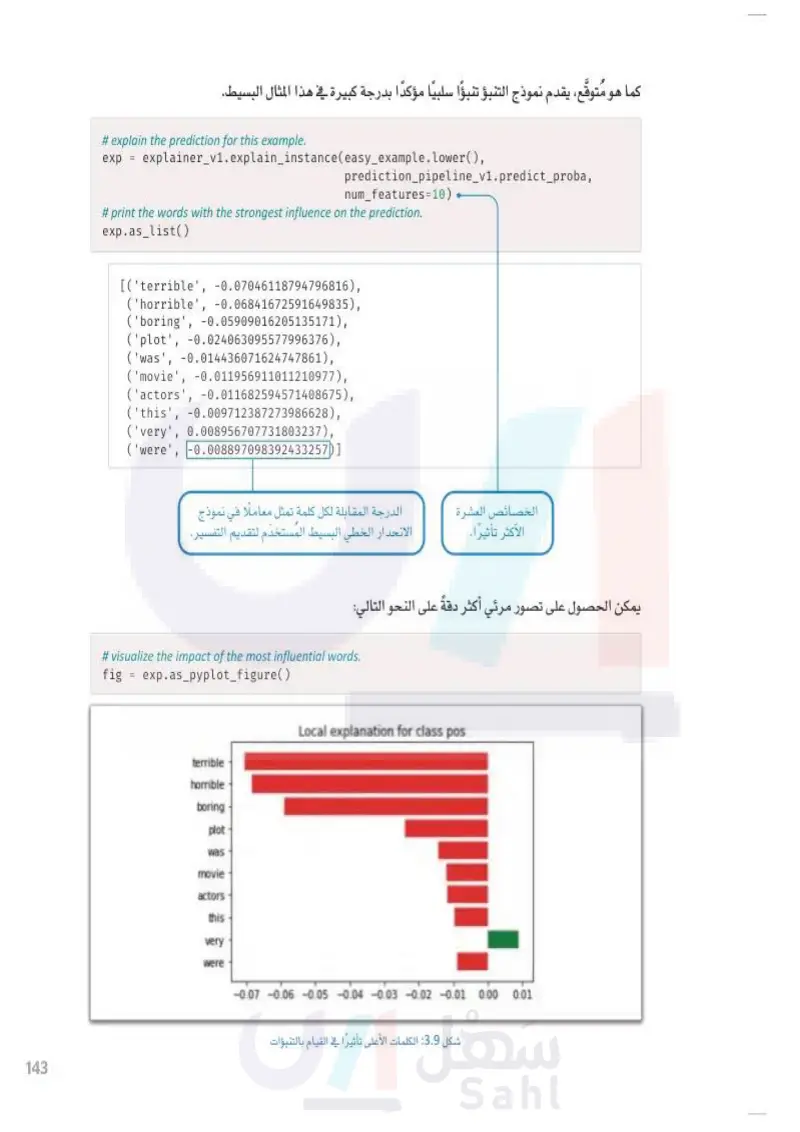
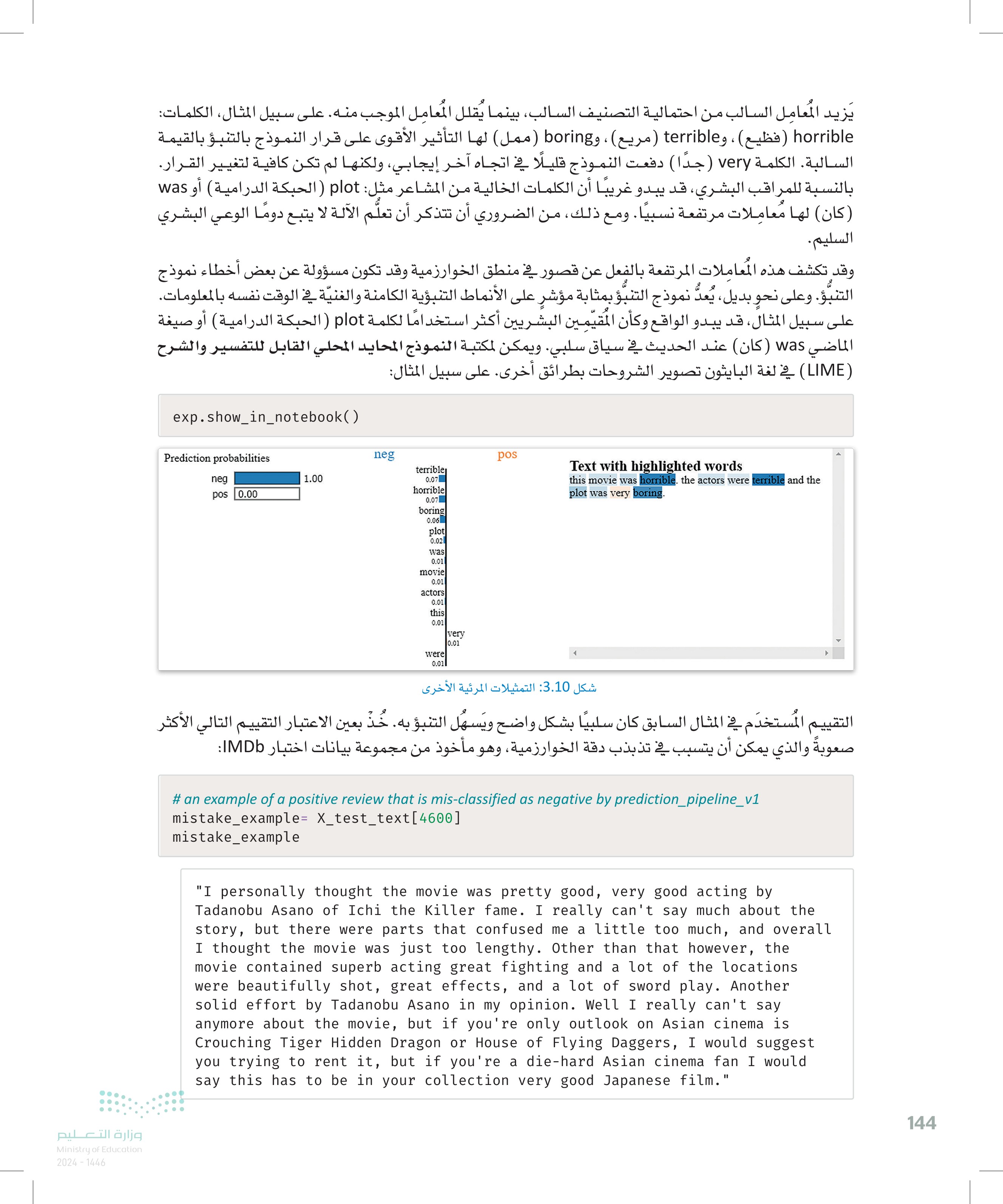
143 وزارة التعليم Ministry of Education 2024-1446 كما هو متوقع، يقدم نموذج التنبؤ تنبؤا سلبيًا مؤكدًا بدرجة كبيرة في هذا المثال البسيط. # explain the prediction for this example. exp = explainer_v1.explain_instance(easy_example.lower(), prediction_pipeline_v1.predict_proba, num_features=10) # print the words with the strongest influence on the prediction. exp.as_list() [('terrible', -0.07046118794796816), ('horrible', -0.06841672591649835), ('boring', -0.05909016205135171), ('plot', -0.024063095577996376), ('was', -0.014436071624747861), ('movie', -0.011956911011210977), ('actors', -0.011682594571408675), ('this', -0.009712387273986628), ('very', 0.008956707731803237), ('were', -0.008897098392433257)] الخصائص العشرة الأكثر تأثيرا. الدرجة المقابلة لكل كلمة تمثل معاملا في نموذج الانحدار الخطي البسيط المُستخدم لتقديم التفسير. يمكن الحصول على تصور مرئي أكثر دقةً على النحو التالي: #visualize the impact of the most influential words. fig = exp.as_pyplot_figure() terrible horrible Local explanation for class pos boring plot was movie actors this very were -0.07 -0.06 -0.05 -0.04 -0.03 -0.02 -0.01 0.00 0.01 شكل :3.9 الكلمات الأعلى تأثيرا في القيام بالتنبؤات

يقدم نموذج التنبؤ تنبؤ سلبيا مؤكدا بدرجة كبيرة في هذا المثال البسيط
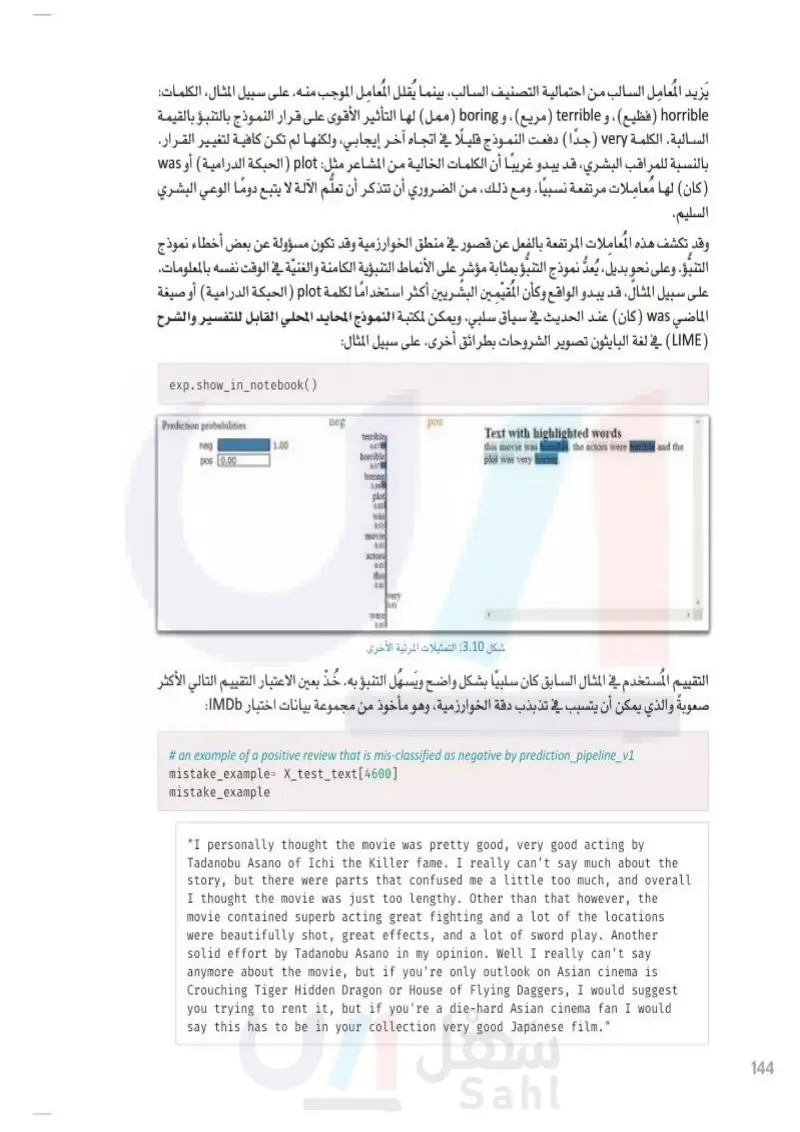
وزارة التعليم Ministry of Education 2024-1446 يَزيد المُعامِل السالب من احتمالية التصنيف السالب، بينما يُقلل المعامل الموجب منه. على سبيل المثال، الكلمات: horrible فظيع ، و terrible مريع ) ، و boring (ممل) لها التأثير الأقوى على قرار النموذج بالتنبؤ بالقيمة السالبة. الكلمة very) (جدا) دفعت النموذج قليلًا في اتجاه آخر إيجابي، ولكنها لم تكن كافية لتغيير القرار. بالنسبة للمراقب البشري، قد يبدو غريبا أن الكلمات الخالية من المشاعر مثل plot (الحبكة الدرامية) أو was (كان) لها مُعاملات مرتفعة نسبيًا. ومع ذلك، من الضروري أن تتذكر أن تعلُّم الآلة لا يتبع دوما الوعي البشري السليم. وقد تكشف هذه المعاملات المرتفعة بالفعل عن قصور في منطق الخوارزمية وقد تكون مسؤولة عن بعض أخطاء نموذج التنبؤ. وعلى نحو بديل، يُعدُّ نموذج التنبؤ بمثابة مؤشر على الأنماط التنبؤية الكامنة والغنيّة في الوقت نفسه بالمعلومات. على سبيل المثال، قد يبدو الواقع وكأن المقيمين البشريين أكثر استخدامًا لكلمة plot ( الحبكة الدرامية) أوصيغة الماضي was ( كان ) عند الحديث في سياق سلبي. ويمكن لمكتبة النموذج المحايد المحلي القابل للتفسير والشرح (LIME) في لغة البايثون تصوير الشروحات بطرائق أخرى. على سبيل المثال: exp.show_in_notebook() Prediction probabilities neg pos 0.00 neg pos terrible 1.00 0.07 horrible 0.07 boring 0.06 plot 0.02 was 0.01 movie 0.01 actors 0.01 this 0.01 very 0.01 were 0.01 Text with highlighted words this movie was horrible. the actors were terrible and the plot was very boring. شكل 3.10: التمثيلات المرئية الأخرى التقييم المستخدم في المثال السابق كان سلبيًا بشكل واضح ويسهل التنبؤ به خُذْ بعين الاعتبار التقييم التالي الأكثر صعوبةً والذي يمكن أن يتسبب في تذبذب دقة الخوارزمية، وهو مأخوذ من مجموعة بيانات اختبار IMDb # an example of a positive review that is mis-classified as negative by prediction_pipeline_v1 mistake_example= X_test_text[4600] mistake_example "I personally thought the movie was pretty good, very good acting by Tadanobu Asano of Ichi the Killer fame. I really can't say much about the story, but there were parts that confused me a little too much, and overall I thought the movie was just too lengthy. Other than that however, the movie contained superb acting great fighting and a lot of the locations were beautifully shot, great effects, and a lot of sword play. Another solid effort by Tadanobu Asano in my opinion. Well I really can't say anymore about the movie, but if you're only outlook on Asian cinema is Crouching Tiger Hidden Dragon or House of Flying Daggers, I would suggest you trying to rent it, but if you're a die-hard Asian cinema fan I would say this has to be in your collection very good Japanese film." 144
يزيد المعامل السالب من احتمالية التصنيف السالب بينما يقلل المعامل الموجب منه
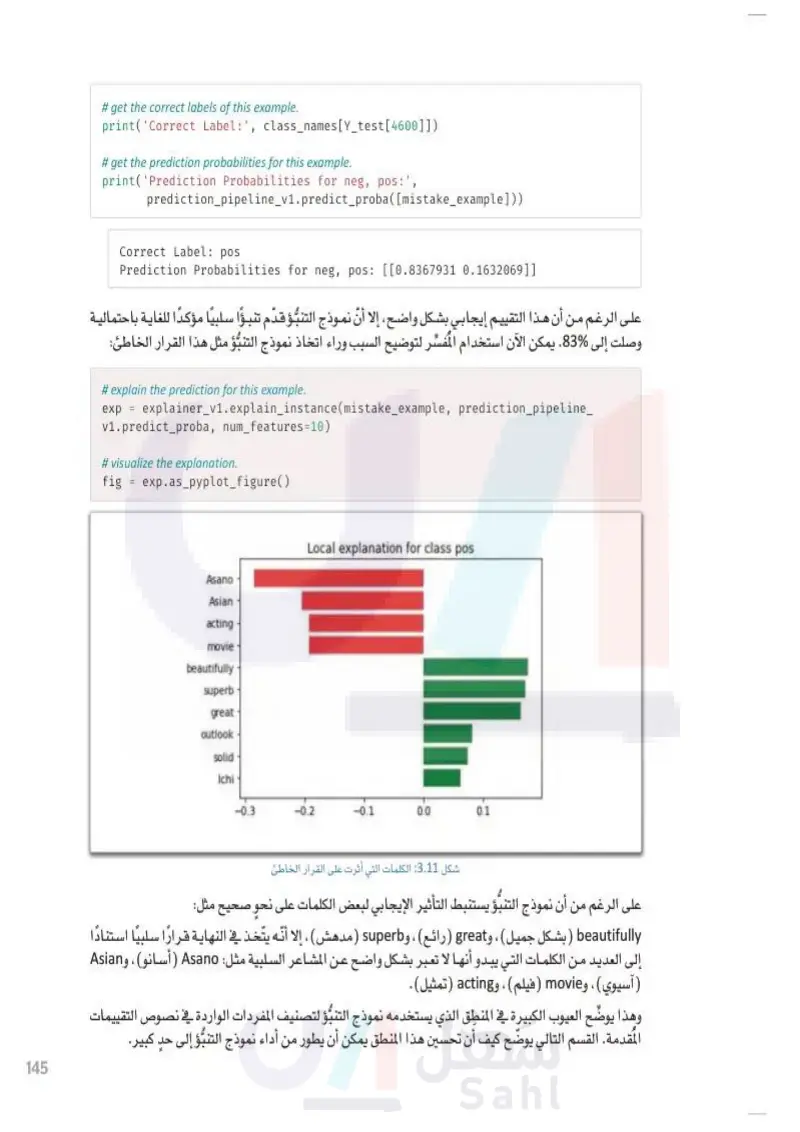
145 وزارة التعليم Ministry of Education 2024-1446 # get the correct labels of this example. print('Correct Label: ', class_names[Y_test[4600]]) # get the prediction probabilities for this example. print('Prediction Probabilities for neg, pos: ', prediction_pipeline_v1.predict_proba([mistake_example])) Correct Label: pos Prediction Probabilities for neg, pos: [[0.8367931 0.1632069]] على الرغم من أن هذا التقييم إيجابي بشكل واضح، إلا أن نموذج التنبؤ قدّم تنبؤا سلبيًا مؤكدًا للغاية باحتمالية وصلت إلى 83. يمكن الآن استخدام المفسِّر لتوضيح السبب وراء اتخاذ نموذج التنبؤ مثل هذا القرار الخاطئ: # explain the prediction for this example. exp = explainer_v1.explain_instance(mistake_example, prediction_pipeline_ v1.predict_proba, num_features=10) # visualize the explanation. fig = exp.as_pyplot_figure() Local explanation for class pos Asano Asian acting movie beautifully superb great outlook solid Ichi -0.3 -0.2 -0.1 0.0 0.1 شكل :3.11 الكلمات التي أثرت على القرار الخاطئ على الرغم من أن نموذج التنبؤ يستنبط التأثير الإيجابي لبعض الكلمات على نحو صحيح مثل: beautifully بشكل جميل ، و great (رائع) ، و superb مدهش) ، إلا أنّه يتّخذ في النهاية قرارًا سلبيًا استنادًا إلى العديد من الكلمات التي يبدو أنها لا تعبر بشكل واضح عن المشاعر السلبية مثل: Asano (أسانو)، و Asian (آسيوي ) ، و movie (فيلم)، و acting (تمثيل). وهذا يوضّح العيوب الكبيرة في المنطق الذي يستخدمه نموذج التنبؤ لتصنيف المفردات الواردة في نصوص التقييمات المقدمة القسم التالي يوضّح كيف أن تحسين هذا المنطق يمكن أن يطور من أداء نموذج التنبؤ إلى حدٍ كبير.

على الرغم من أن هذا التقييم إيجابي بشكل واضح الا أن نموذج التنبؤ قدم تنبؤ سلبيا مؤكدا
تحسين البرمجة الاتجاهية للنصوص Improving Text Vectorization استخدم الإصدار الأول لخط أنابيب التنبؤ أداة CountVectorizer لحساب عدد المرات التي تظهر فيها كل كلمة في كل تقييم. تتجاهل هذه التعبير النمطي (Regular Expression ) : المنهجية حقيقتين أساسيتين حول اللغات البشرية • قد يتغير معنى الكلمة وأهميتها حسب الكلمات المستخدمة معها. التعبير النمطي هو نمط نص يُستخدم لمطابقة ولمعالجة سلاسل النصوص وتقديم طريقة موجزة ومرنة لتحديد أنماط النصوص، كما تُستخدم على نطاق واسع في معالجة النصوص • تكرار الكلمة في المستند لا يُعدُّ دومًا تمثيلا دقيقًا لأهميتها. على سبيل المثال، على الرغم من أن تكرار كلمة great (رائع) مرتين قد يمثل وتحليل البيانات. مؤشرًا إيجابيًا في مستند يحتوي على 100 كلمة، إلا أنه يمثل مؤشرًا أقل أهمية بكثير في مستند يحتوي على 1000 كلمة. سيشرح هذا الجزء كيفية تحسين البرمجة الاتجاهية للنصوص لأخذ هاتين الحقيقتين في عين الاعتبار. يستدعي المقطع البرمجي التالي ثلاثة مكتبات مختلفة بلغة البايثون، ستستخدم لتحقيق ذلك: • nltk وجينسم ( Gensim) : تُستخدم هاتان المكتبتان الشهيرتان في مهام معالجة اللغات الطبيعية المتنوّعة. • :re تُستخدم هذه المكتبة في البحث عن النّصوص، ومعالجتها باستخدام التعبيرات النمطية. %%capture !pip install nltk #install nltk !pip install gensim # install gensim import nltk # import nltk nltk.download('punkt') # install nltk's tokenization tool, used to split a text into sentences. import re #import re from gensim.models.phrases import Phrases, ENGLISH_CONNECTOR_WORDS # import tools from the gensim library. تحديد العبارات Detecting Phrases يمكن استخدام الدالة الآتية لتقسيم مستند محدد التقسيم (Tokenization) : يقصد به عملية تقسيم البيانات النصية إلى أجزاء مثل كلمات، إلى قائمة من الجُمل المقسَّمة، حيث يمكن تمثيل كل وجُمل، ورموز، وعناصر أخرى يطلق عليها الرموز (Tokens). # convert a given doc to a list of tokenized sentences. def tokenize_doc(doc: str): return [re.findall(r'\b\w+\b', جملة مُقسمة بقائمة من الكلمات: دالة ()sent_tokenize تقسم المستند إلى قائمة من الجمل. sent.lower()) for sent in nltk.sent_tokenize(doc)] دالة ( ) sent_tokenize من مكتبة nltk تُقسِّم المستند إلى قائمة من الجمل. بعد ذلك، يتم كتابة كل جملة بأحرف صغيرة وتغذيتها إلى دالة ( ) findall من مكتبة re لتقوم بتحديد تكرارات التعبيرات النمطية w+\b\\ . ستختبرها على السلسلة النصية الموجودة في متغير raw_text. في هذا السياق وزارة التعليم Ministry of Education 2024-1446 146

تحسين البرمجة الاتجاهية للنصوص
تحديد العبارات
• تتطابق مع كل الرموز الأبجدية الرقمية - - - والشرطة السفلية. +w\ تُستخدم للبحث عن واحد أو أكثر من رموز .. لذلك، في السلسلة النصية hello123_world (مرحبا 123 العالم) ، النمط +W\+ سيتطابق مع الكلمات hello مرحبا ) و 123 وworld (العالم). b تمثل الفاصل (Boundry) بين رمز \ ورمز ليس \ ، وكذلك في بداية أو نهاية السلسلة النصية المعطاة. على سبيل المثال: سيتطابق النمط cat مع الكلمة cat (القطة) في السلسلة النصية The cat is cute (القطة لطيفة ) ، ولكنه لن يتطابق مع الكلمة cat (القطة) في السلسلة النصية The category is pets (فئة الحيوانات الأليفة). أدناه مثالًا على التقسيم باستخدام الدالة ( )tokenize_doc raw_text='The movie was too long. I fell asleep after the first 2 hours.' tokenized_sentences=tokenize_doc(raw_text) tokenized sentences [['the', 'movie', 'was', 'too', 'long'], 'first', '2', 'hours']] ['i', 'fell', 'asleep', 'after', 'the', 'first', '2', يمكن الآن تجميع الدالة ( )tokenize_doc مع أداة العبارات من مكتبة جينسم ( Gensim) لإنشاء نموذج العبارة، وهو نموذج يمكنه التعرّف على العبارات المكونة من عدة كلمات في جملة معطاة. يستخدم المقطع البرمجي التالي بيانات التدريب IMDB الخاصة بـ (train_text_ لبناء مثل هذا النموذج: sentences=[] # list of all the tokenized sentences across all the docs in this dataset for doc in X_train_text: # for each doc in this dataset sentences+=tokenize_doc(doc) # get the list of tokenized sentences in this doc # build a phrase model on the given data imdb_phrase_model = Phrases(sentences, 1 connector_words=ENGLISH_CONNECTOR_WORDS, 2 scoring='npmi', 3 threshold=0.25).freeze ( ) (4) كما هو موضح بالأعلى، تستقبل الدالة ( ) Phrases أربعة متغيرات: 1 قائمة الجُمل المُقسَّمة من مجموعة النصوص المعطاة. قائمة بالكلمات الإنجليزية الشائعة التي تظهر بصورة متكررة في العبارات مثل: the ، و of ) ، وليس لها أي قيمة موجبة أو سالبة ، ولكن يمكنها إضفاء المشاعر حسب السياق، ولذلك يتم التعامل معها بصورة مختلفة. تُستخدم دالة تسجيل النقاط لتحديد ما إذا كان تضمين مجموعة من الكلمات في العبارة نفسها واجبًا. المقطع البرمجي بالأعلى يستخدم مقياس المعلومات النقطية المشتركة المعاير Normalized Pointwise Mutual Information - (NPMI) لهذا الغرض. يستند هذا المقياس على تكرار توارد الكلمات في العبارة المرشحة وتكون قيمته بين 1 ويرمز إلى الاستقلالية الكاملة (Complete Independence) ، و 1+ ويرمز إلى التوارد الكامل (Complete Co-occurrence). في حدود دالة تسجيل النقاط يتم تجاهل العبارات ذات النقاط الأقل. ومن الناحية العملية، يمكن ضبط هذه الحدود لتحديد القيمة التي تُعطي أفضل النتائج في التطبيقات النهائية مثل: النمذجة التنبؤية. تُحوِّل دالة ()freeze نموذج العبارة إلى تنسيق غير قابل للتغيير أي مُجمد (Frozen) لكنّه أكثر سرعة. 147 وزارة التعليم Ministry of Education 2024-1446
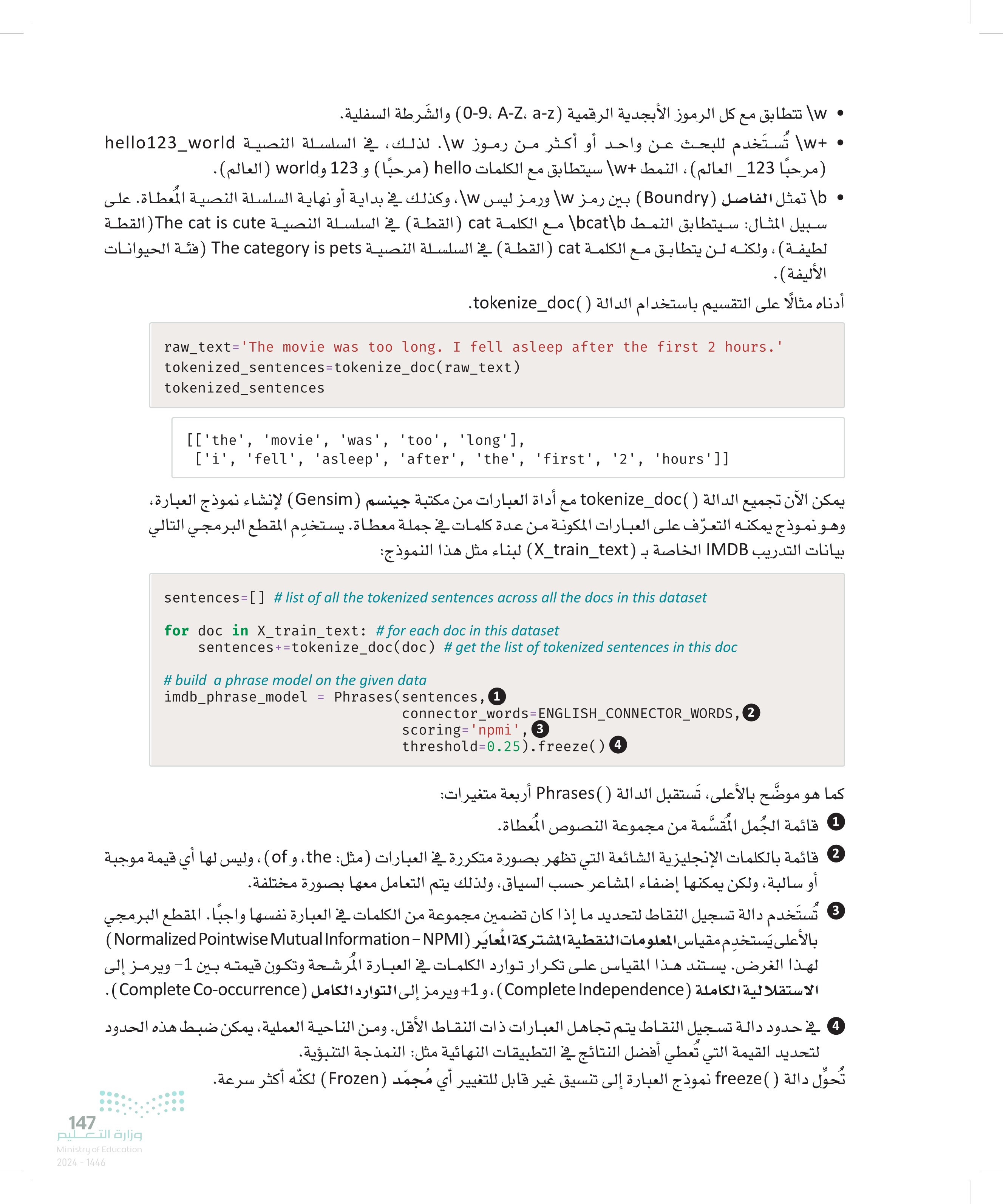
كتابة كل جملة بأحرف صغيرة وتغذيتها الى دالة findall() من مكتبة re لتقوم تحديد تكرارات 1
وزارة التعليم Ministry of Education 2024-1446 عند تطبيقها على الجملتين المقسَّمتين بالمثال الموضح بالأعلى، سيُحقق نموذج العبارة النتائج التالية: imdb_phrase_model[tokenized_sentences[0]] ['the', 'movie', 'Was', 'too_long'] imdb_phrase_model[tokenized_sentences[1]] ['i', 'fell_asleep', 'after', 'the', 'first', '2_hours'] يحدد نموذج العبارة ثلاثة عبارات على النحو التالي: fell_asleep ( سقط نائما ) و too_long (طويل جدا ) ، وhours 2-ساعة) وجميعها تحمل معلومات أكثر من كلماتها المفردة. على سبيل المثال، تحمل عبارة too_long (طويل جدًا) مشاعر سلبية واضحة، على الرغم من أن كلمتي too (جدا) و long (طويل) لا تعبران عن ذلك منفردتين، وبالمثل، فعلى الرغم من أن كلمة asleep نائم) في مراجعة الفيلم تمثل دلالة سلبية، فالعبارة fell_asleep (سقط نائمًا ) توصل رسالة أكثر وضوحًا. وأخيرًا ، تستنبط من hours_2 محايد too السياق fell السياق + long too_long محايد سلبي مُقسَّم سلبي سلبي مُقسَّم السياق المحدد + asleep السياق مُقسَّم + hours 2 | fell_asleep 2_hours (2-ساعة ) سياقًا أكثر تحديدا من الكلمتين 2 شكل 3.12 المشاعر الإيجابية والسلبية قبل التقسيم وبعده و hours كل على حدة. تستخدم الدالة التالية إمكانية تحديد العبارات بهذا الشكل لتفسير العبارات في وثيقة معطاه: def annotate_phrases(doc:str, phrase_model): sentences=tokenize_doc(doc )# split the document into tokenized sentences. tokens [] # list of all the words and phrases found in the doc for sentence in sentences: # for each sentence # use the phrase model to get tokens and append them to the list. tokens+=phrase_model[sentence] return .join(tokens) #join all the tokens together to create a new annotated document. يستخدم المقطع البرمجي التالي دالة ( ) annotate_phrases لتفسير كل من تقييمات التدريب والاختبار من مجموعة بيانات IMDb. # annotate all the test and train reviews. X_train_text_annotated=[annotate_phrases(doc,imdb_phrase_model) for doc in x_ train_text] x_test_text_annotated=[annotate_phrases(text,imdb_phrase_model)for text in X test_text] 148
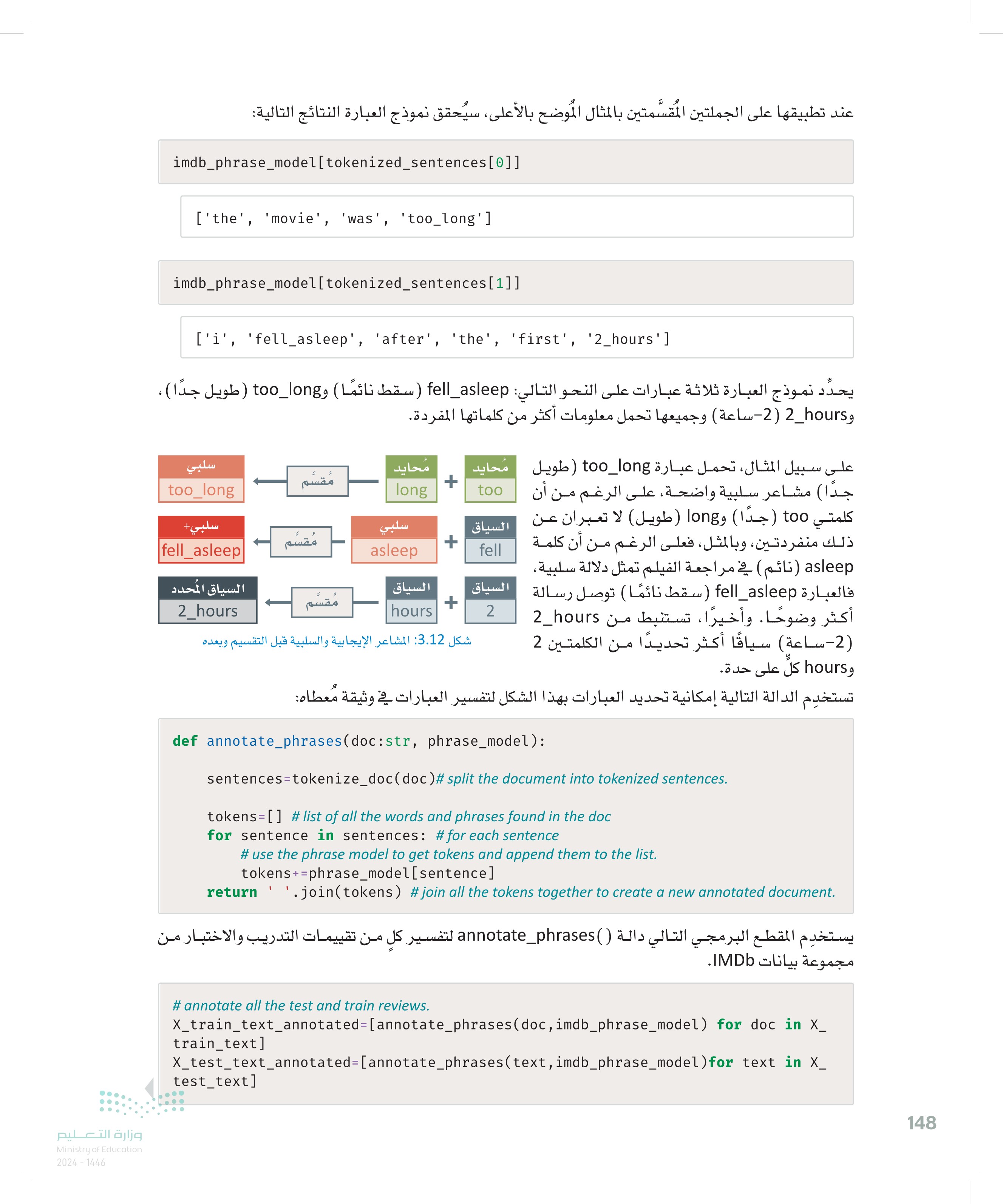
عند تطبيقها على الجملتين المقسمتين بالمثال الموضح بالأعلى سيحقق نموذج العبارة النتائج التالية
149 # an example of an annotated document from the imdb training data x_train_text_annotated[0] 'i_grew up b 1965 watching and loving the thunderbirds all my_mates at school watched we played thunderbirds before school during lunch and after school we all wanted to be virgil or scott no_one wanted to be alan counting down from 5 became an art_form i took my children to see the movie hoping they would get_a_glimpse of what i loved as a child how bitterly disappointing the only high_point was the snappy theme_tune not that it could compare with the original score of the thunderbirds thankfully early saturday_mornings one television_channel still plays reruns of the series gerry_anderson and his wife created jonatha frakes should hand in his directors chair his version was completely hopeless a waste of film utter_rubbish a cgi remake may_be acceptable but replacing marionettes with homo_sapiens subsp sapiens was a huge error of judgment' المستند استخدام مقياس تكرار المصطلح - تكرارا العكسي في البرمجة الاتجاهية للنصوص Using TF-IDF for Text Vectorization تكرار المصطلح - تكرار المستند العكسي Term Frequency Inverse Document : Frequency (TF-IDF) تكرار الكلمة في المستنَد لا يُعدُّ دومًا تمثيلا دقيقًا لأهميتها . الطريقة المثلى تكرار المصطلح - تكرار المستند العكسي هو لتمثيل التكرار هي المقياس الشهير لتكرار المصطلح - تكرار المستند طريقة تُستخدم لتحديد أهمية الرموز في المستند. المستندات. العكسي .(TF-IDF). يستخدم هذا المقياس صيغة رياضية بسيطة لتحديد أهمية الرموز مثل: الكلمات أو العبارات في المستند بناءً على عاملين: تكرار الرمز في المستند، بقياس عدد مرات ظهوره في المستند مقسومًا على إجمالي عدد الرموز في جميع تكرار المستند العكسي للرمز المحسوب بقسمة إجمالي عدد المستندات في مجموعة البيانات على عدد المستندات التي تحتوي على الرمز. العامل الأول يتجنب المبالغة في تقدير أهمية المصطلحات التي تظهر في الوثائق الأطول، أما العامل الثاني فيستبعد المصطلحات التي تظهر في كثير من المستندات، مما يساعد على إثبات حقيقة أن بعض الكلمات هي أكثر شيوعًا من غيرها. المصطلح الأصل النصى (Corpus) الكلمة المستند شكل 3.13: الكلمات والمصطلحات الواردة في المستند تكرار المستند العكسي : = عدد ،د المستندات في الأصل النصي عدد المستندات التي تحتوي على المصطلح عدد مرات ظهور المصطلح في المستند تكرار المصطلح : عدد الكلمات في المستند وزارة التعليم Ministry of Education 2024-1446 أداة TfidfVectorizer تكرار المصطلح » تكرار المستند العكسي = القيمة توفر مكتبة سكليرن (Sklearn) أداة تدعم هذا النوع من البرمجة الاتجاهية لتكرار المصطلح تكرار المستند لل العكسي (TF-IDF) . يمكن استخدام أداة TfidfVectorizer لتمثيل عبارة باستخدام المتجهات. from sklearn.feature_extraction.text import TfidfVectorizer # Train a TF-IDF model with the IMDb training dataset vectorizer_tf = TfidfVectorizer(min_df=10) vectorizer_tf.fit(X_train_text_annotated) X_train_tf = vectorizer_tf.transform(X_train_text_annotated)

يستخدم المقطع البرمجي التالي دالة annotate_phrases() لتفسير كل من تقييمات التدريب والاختبار من مجموعة بيانات IMDb. 1
استخدام مقياس تكرار المصطلح - تكرار المستند العكسي في البرمجة الاتجاهية للنصوص
أداة TfidVectorizer
وزارة التعليم Ministry of Education 2024-1446 يمكن الآن إدخال أداة التمثيل بالمتجهات في مُصنَّف بايز الساذج لبناء خط أنابيب نموذج تنبؤ جديد وتطبيقه على بيانات اختبار IMDb # train a new Naive Bayes Classifier on the newly vectorized data. model_tf Multinomial NB() model_tf.fit(X_train_v2, Y_train) # create a new prediction pipeline. prediction_pipeline_tf = make_pipeline(vectorizer_tf, model_tf) # get predictions using the new pipeline. predictions_tf = prediction_pipeline_tf.predict(X_test_text_annotated) # print the achieved accuracy. accuracy_score (Y_test, predictions_tf) 0.8858 يحقق خط الأنابيب الجديد دقة تصل إلى 88.58 ، وهو تحسن كبير بالمقارنة مع الدقة السابقة التي وصلت إلى 84.68%. يمكن الآن استخدام النموذج المحسن لإعادة النظر في مثال الاختبار الذي تم تصنيفه بشكل خاطئ بواسطة النموذج الأول: # get the review example that confused the previous algorithm mistake_example_annotated=X_test_text_annotated[4600] print('\nReview: ', mistake_example_annotated) #get the correct labels of this example. print('\nCorrect Label:', class_names [Y_test[4600]]) # get the prediction probabilities for this example. print('\nPrediction Probabilities for neg, pos:', prediction_pipeline_ tf.predict_proba([mistake_example_annotated])) Review: i personally thought the movie was pretty good very_good acting by tadanobu_ asano of ichi_the_killer fame i really can_t say much about the story but there_were parts that confused me a little_too much and overall i thought the movie was just too lengthy other_than that however the movie contained superb_acting great fighting and a lot of the locations were beautifully_shot great effects and a lot of sword play another solid effort by tadanobu_asano in my opinion well i really can_t say anymore about the movie but if you re only outlook on asian_cinema is crouching_tiger hidden_ dragon or house of flying_daggers i_would suggest you trying to rent_it but if you re a die hard asian_cinema fan i would say this has to be in your_collection very good japanese film Correct Label: pos Prediction Probabilities for neg, pos: [[0.32116538 0.67883462]] 150

يمكن الآن إدخال أداة التمثيل بالمتجهات في مصنف بايز الساذج لبناء خط أنابيب نموذج تنبؤ جديد
151 وزارة التعليم Ministry of Education 2024-1446 يتنبأ خط الأنابيب الجديد بشكل صحيح بالقيمة الإيجابية لهذا التقييم. يستخدم المقطع البرمجي التالي مفسر النموذج المحايد المحلي القابل للتفسير والشرح (LIME) لتفسير المنطق وراء هذا التنبؤ # create an explainer. explainer_tf = LimeTextExplainer(class_names=class_names) # explain the prediction of the second pipeline for this example. exp = explainer_tf.explain_instance(mistake_example_annotated, prediction_ pipeline_tf.predict_proba, num_features=10) # visualize the results. fig = exp.as_pyplot_figure() superb_acting beautifully_shot can_t very good die_hard your_collection other than solid outlook Local explanation for class pos ااا great -0.02 0.00 0.02 0.04 0.06 شكل 3.14: تأثير الكلمة في مزيج تكرار المصطلح - تكرار المستند العكسي ومصنّف بايز الساذج تؤكد النتائج أن خط الأنابيب الجديد يتبع منطقًا أكثر ذكاءً. فهو يُحدد بشكل صحيح المشاعر الإيجابية للعبارات مثل: beautifully_shot (لقطة - جميلة ، و superb_acting تمثيل_رائع) ، و very good جيد جدا ) ، ولا يمكن تضليله باستخدام الكلمات التي جعلت خط الأنابيب الأول يتنبأ بنتائج خاطئة. يمكن تحسين أداء خط الأنابيب لنموذج التنبؤ بطرائق متعددة، بإستبدال مصنف بايز البسيط بطرائق أكثر تطورًا مع ضبط متغيراتها لزيادة احتمالاتها . وثمة خيار آخر يتلخص في استخدام تقنيات البرمجة الاتجاهية البديلة التي لا تستند إلى تكرار الرمز، مثل تضمين الكلمات والنصوص، وسيُستعرض ذلك في الدرس التالي.

يتنبأ خط الأنابيب الجديد بشكل صحيح بالقيمة الايجابية لهذا التقييم
152 1 2 تمرينات حدد الجملة الصحيحة والجملة الخاطئة فيما يلي: 1. في التعلُّم الموجّه تُستخدم مجموعات البيانات المعنونة لتدريب النموذج. لک 2. البرمجة الاتجاهية هي تقنية لتحويل البيانات من تنسيق متَّجه رقمي إلى بيانات أولية. 3. تتطلب المصفوفة المتباعدة ذاكرة أقل بكثير من المصفوفة الكثيفة. .4 تُستخدم خوارزمية مُصنَّف بايز الساذج لبناء خط أنابيب التنبؤ. 5 تكرار الكلمة في المستند يعدّ التمثيل الدقيق الوحيد لأهمية هذه الكلمة. اشرح لماذا تتطلب المصفوفة الكثيفة مساحة من الذاكرة أكبر من المصفوفة المتباعدة. صحيحة خاطئة 3 حلل كيف يُستخدم العاملان الرياضيان في تكرار المصطلح- تكرار المستند العكسي (TF-IDF) لتحديد أهمية الكلمة في النص. وزارة التعليم Ministry of Education 2024-1446

حدد الجملة الصحيحة والجملة الخاطئة فيما يلي: في التعلم الموجه تستخدم مجموعات البيانات المعنونة لتدريب النموذج

اشرح لماذا تتطلب المصفوفة الكثيفة مساحة من الذاكرة أكبر من المصفوفة المتباعدة
حلل كيف يستخدم العاملان الرياضيان في تكرار المصطلح - تكرار المستند العكسي لتحديد أهمية الكلمة في النص
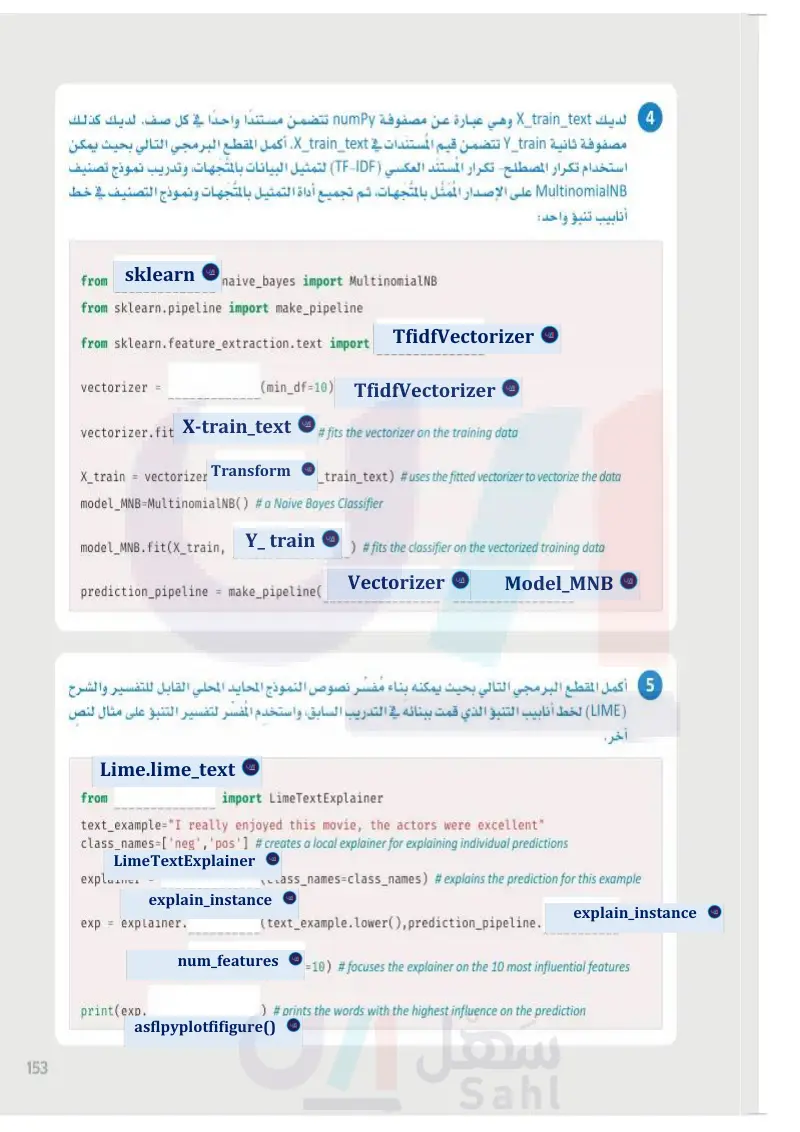
153 لديك X_train_text وهي عبارة عن مصفوفة numpy تتضمن مستندًا واحدًا في كل صف. لديك كذلك مصفوفة ثانية Y_train تتضمن قيم المستندات في X_train_text . أكمل المقطع البرمجي التالي بحيث يمكن استخدام تكرار المصطلح تكرار المستند العكسي (TF-IDF) لتمثيل البيانات بالمتجهات، وتدريب نموذج تصنيف MultinomialNB على الإصدار الممثل بالمتجهات، ثم تجميع أداة التمثيل بالمتجهات ونموذج التصنيف في خط أنابيب تنبؤ واحد : from . naive_bayes import MultinomialNB from sklearn.pipeline import make_pipeline from sklearn.feature_extraction.text import vectorizer (min_df=10) vectorizer.fit( X_train = vectorizer. ) # fits the vectorizer on the training data (x_train_text) # uses the fitted vectorizer to vectorize the data model_MNB=MultinomialNB() # a Naive Bayes Classifier model_MNB.fit(X_train, prediction_pipeline = make_pipeline( ) #fits the classifier on the vectorized training data أكمل المقطع البرمجي التالي بحيث يمكنه بناء مُفسِّر نصوص النموذج المحايد المحلي القابل للتفسير والشرح (LIME) لخط أنابيب التنبؤ الذي قمت ببنائه في التمرين السابق، واستخدم المفسِّر لتفسير التنبؤ على مثال لنص وزارة التعليم Ministry of Education 2024-1446 آخر. from import LimeTextExplainer text_example="I really enjoyed this movie, the actors were excellent" class_names=['neg', 'pos'] # creates a local explainer for explaining individual predictions explainer = exp explainer. print(exp. (class_names=class_names) # explains the prediction for this example (text_example.lower(),prediction_pipeline. =10) # focuses the explainer on the 10 most influential features ) # prints the words with the highest influence on the prediction 5 4

لديك X_train_text وهي عبارة عن مصفوفة numPy تتضمن مستنداً واحداً في كل صف
أكمل المقطع البرمجي التالي بحيث يمكنه بناء مفسر نصوص النموذج المحايد المحلي القابل للتفسير واشلرح